Codex Pulling Ahead of Claude Code? Read the 2026 Shift
Three creators flipped to Codex the same day; r/ClaudeAI hit thousands of upvotes on PR-review fatigue. Stack shift, or review-loop shift?
Three independent creators all dropped “Codex is pulling ahead of Claude Code” takes on the same day this week. Nate B Jones and Tibo did a head-to-head and concluded that Codex was the daily driver now. Chase AI’s “Time to Switch?” workshop went out the same morning. A third creator landed a Claude-Code-to-Codex switch post on Medium, arguing that Codex’s /goal command and 4x token efficiency made the choice obvious. Three creators, one direction, one day.
Meanwhile, r/ClaudeAI hit thousands of upvotes on a single post about the operator emotion underneath all of this: devs are tired of reviewing AI-generated PRs they didn’t initiate. Brian Douglas’s “Death by a Thousand AI Pull Requests” Substack from the open-source side made the same point in a different vocabulary. The category moment isn’t “Codex won.” It’s “the agent-PR-review loop broke, and we’re sorting out which agent fits which seat in that loop.”
This piece reads that moment cleanly. What actually changed in the last 14 days, what didn’t change, and the operator question that matters: does the answer reroute your stack — or your review process?
What actually changed in the last 14 days
Three concrete things landed in the May 2026 window.
Codex’s /goal command crossed the autonomy threshold. Up until April, Codex’s autonomous loop topped out around 20-30 minute runs before drifting. The May Codex release tightened the plan-act-test-review cycle enough that it now sustains multi-hour autonomous sessions on the right kind of task — codebase-wide migrations, dependency upgrades, test backfills. The New Stack tested it on a real Python codebase and called it “the strongest Claude Code rival yet” — explicitly framing it as a daily-driver shift, not a benchmark win. The benchmarks themselves moved with it: GPT-5.5 now leads SWE-bench Verified at 88.7%, edging Claude Opus 4.7’s 87.6%, and leads Terminal-Bench at 82.7%.
The cost gap widened in a single direction. A widely-circulated Express.js refactor benchmark cost roughly $15 on Codex versus $155 on Claude Code for the same task — a 10x gap. The token-per-task delta isn’t subtle anymore. For a small team running a daily-driver coding agent 4-8 hours a day, that gap is the difference between $200/month and $2,000/month in agent costs. The math now lands in a place where switching cost can be paid back in a single billing cycle.
The Anthropic skills ecosystem kept compounding. Even as Codex pulled ahead on raw daily-driver mechanics, Anthropic shipped Code Review and the broader skills directory race kept tilting toward the Claude ecosystem. Mitchell Hashimoto’s skill stack, the tech-leads-club agent-skills registry, and obra/superpowers all sit in the Claude orbit. That ecosystem doesn’t move when daily-driver preference shifts. It’s a separate moat operating on a separate timeline.
So three things shifted, and one didn’t. The takes converging on “Codex won” are reading the first three and ignoring the fourth.
What didn’t change
Three things stayed put.
Anthropic still owns the model-quality consensus. Polymarket’s end-of-May “best AI model” market has Anthropic at ~82%, Google at ~19%, OpenAI well behind. That’s not a benchmark consensus — that’s a money-weighted consensus across thousands of traders pricing the actual perception of model leadership. Anthropic also holds SWE-bench Pro at 64.3% vs GPT-5.5’s 58.6% — a 5.7-point gap on the harder, less-saturated benchmark. The “Codex pulled ahead” takes are talking about the coding agent runtime, not the underlying model. Conflating the two is the most common error in this week’s coverage.
Code quality on the produced output still favors Claude. Blind reviews of completed work rated Claude Code’s output cleaner 67% of the time to Codex’s 25%. That gap shows up most on frontend UI work, refactors that need to match an existing codebase’s idiom, and any task where the diff has to read well to a human reviewer six months later. Codex ships the feature faster and cheaper. Claude ships a smaller, cleaner diff. If your downstream cost is “code that future engineers can actually maintain,” the trade isn’t obvious.
The skills ecosystem is still gravitationally Anthropic-aligned. This week’s GitHub trending told the same story — the skills-folder repos kept dominating, Zerostack’s pure-Rust coding agent hit HN at 499 points framed as an Anthropic-ecosystem alternative, and the agent-runtime category overall stayed weighted toward Claude-orbit tooling. Codex has the daily-driver crown. The surrounding ecosystem isn’t migrating with it on the same timeline.
The PR-review meme is doing the actual work
Now the part most of the comparison posts skip.
The signal that’s traveling fastest this week isn’t a Codex review. It’s the r/ClaudeAI PR-review fatigue thread, echoed by Brian Douglas’s “Death by a Thousand AI Pull Requests” on Substack. The operator emotion is consistent: agents are generating PRs faster than humans can meaningfully review them. The unit of work that’s becoming the bottleneck isn’t writing code — it’s reading code you didn’t write and forming judgment on whether to merge it.
That’s a different problem from “which agent should I use.” It’s a workflow problem, and it doesn’t care which model wrote the diff.
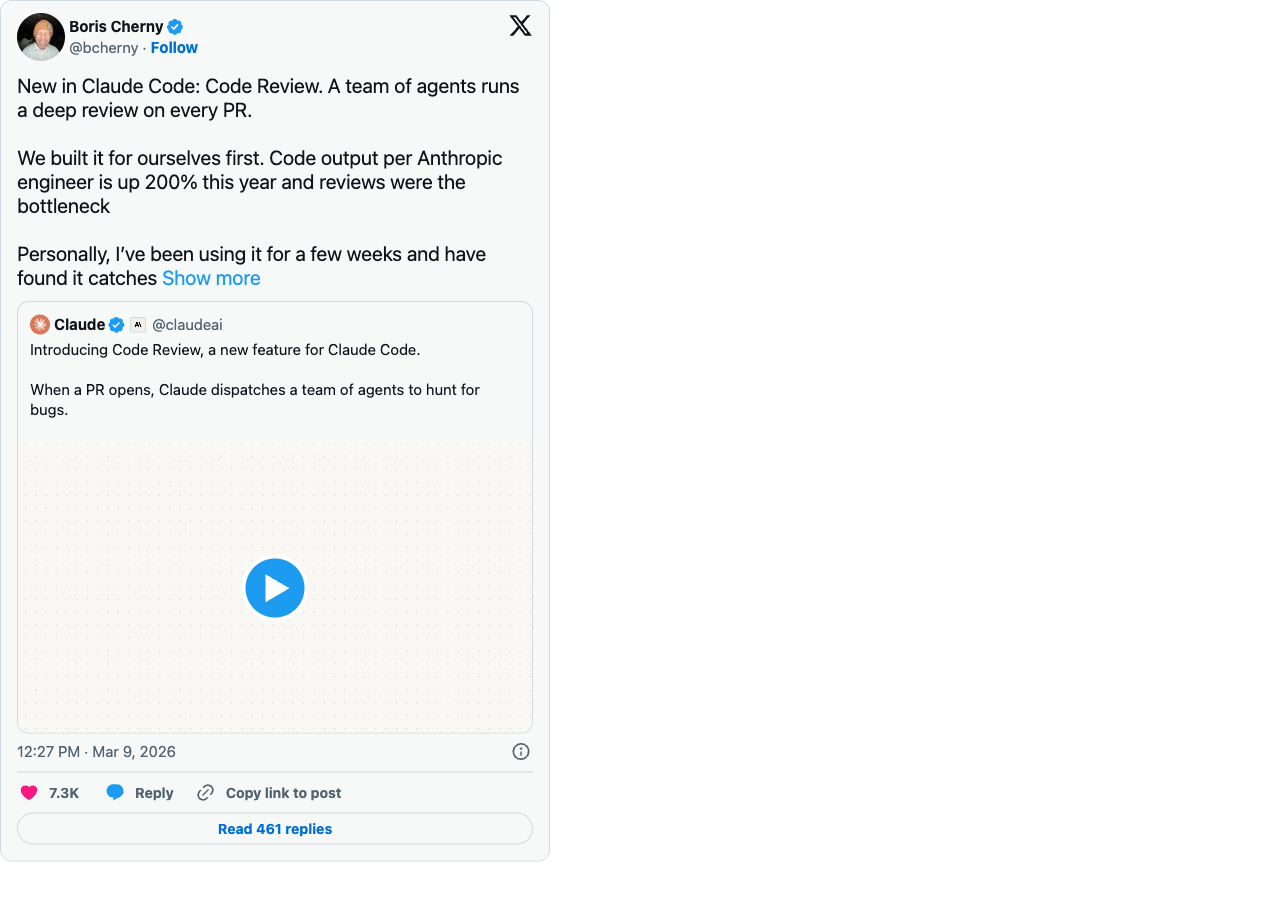
Anthropic’s response to this — Code Review for Claude Code, launched March 9 2026 — is interesting precisely because it’s not a competing-agent feature. It’s a competing-reviewer feature. Boris Cherny’s framing on the launch is direct: code output per Anthropic engineer is up 200% this year, and reviews became the bottleneck. The fix is more agents, on the other side of the diff.
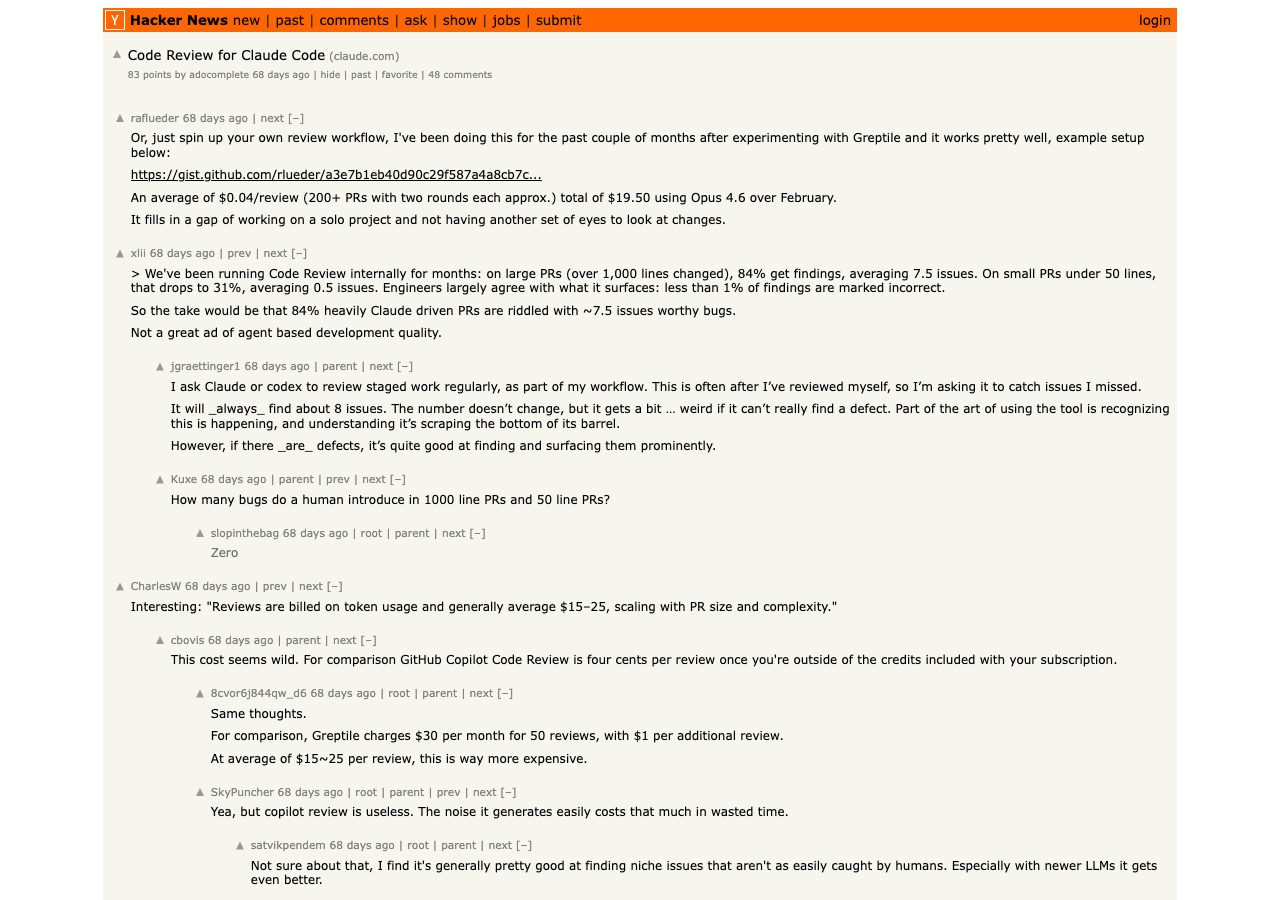
The HN thread on the launch made the deeper question explicit, and most of the top comments landed on it: if the same vendor’s agent both writes and reviews the code, is that even review? One commenter put it bluntly: “Why didn’t the AI write the correct code in the first place?” Another: “So their business model is to deliver me buggy code and then charge me to fix it?” The skepticism is reasonable. The fact that it costs $15-25 per PR review is also a real cost line a team has to plan for.
But the operator framing matters here. The PR-review bottleneck is real, the human-review channel is genuinely saturated on teams shipping ~30+ agent-PRs/day, and “agent reviews agent” isn’t the only option — it’s just the only option that exists today. The teams that solve this first will be the ones that take the review loop as seriously as the generation loop, which most teams currently don’t.
Does this change your stack, or your review loop?
That’s the operator question this week’s convergence actually poses. The two have different answers.
On the stack question: probably not, for most teams. If you’re running a Claude Code stack today and shipping, the right move is to add Codex as a second daily-driver rather than switch wholesale. The tokenmaxxing pattern we covered last month is the canonical version: route long-horizon autonomous tasks to Codex (where the /goal loop pays off and the token math wins), route quality-sensitive refactors and frontend work to Claude (where the cleaner-diff bias pays off), and keep skills/MCP infrastructure on the Anthropic side. The 500-Reddit-developer survey from this week confirms the pattern — 65% prefer Codex for daily coding, but most serious teams run both. The $20+$20/month Pro-subscription combo is the unsexy answer that’s quietly winning.
If you’re starting fresh, the calculus is different. A team that’s never paid Claude Code’s per-seat plan and can architect around Codex’s autonomous loop from day one will save real money. But that’s not the median team this week.
On the review-loop question: yes, this is the move you should make first. Specifically:
-
Measure your current PR-review queue. How many agent-generated PRs hit your repo per day? What’s the average human-eyeball time per PR? If you’re past ~10 PRs/day and human review is sub-3-minutes, you’re already in the saturation zone — the merge is becoming a rubber-stamp regardless of whether you’ve named the problem.
-
Decide what “agent reviews agent” looks like for you. Claude Code Review is the most polished option today. The alternative is rolling your own with a second agent in CI (which works fine for most teams). Either way, the goal is a second pass with different incentives — bug-hunting incentives, not generation incentives. Don’t let the same agent write and approve.
-
Set a per-PR cost budget. $15-25 per review at Claude Code Review pricing is meaningful at scale. A 30-PR/day team is looking at ~$500/day in review costs if it runs on every PR. The right move is per-PR-size tiering: heavy review on PRs over 200 LOC, lightweight review under that. Build the tiering into the merge process.
-
Reclaim human review for the things humans uniquely do. Architecture-level judgment, intent verification, and “is this the right feature” calls aren’t review-agent territory — they’re senior-engineer territory. The point of the review-agent layer is to free that time up, not to replace it.
That’s the actionable read on this week’s convergence. The Codex-vs-Claude-Code debate is real but mostly resolves to “run both.” The PR-review-loop problem is real and resolves to “build the review layer, don’t let it stay implicit.”
The market read
A last note on the framing wars. Every six months in 2026, one of the major agent vendors has a two-week stretch of dominant takes. February was Claude Code’s. April was Codex Mobile’s. This week is Codex’s again. The pattern in each cycle is the same: a feature ships that genuinely moves the daily-driver line, three creators converge on the same take within 48 hours, and the take then calcifies into “X won” framing that lasts about three weeks before the next vendor releases something.
If you’re building product around AI coding agents, you should expect this cadence to continue through the year and not over-fit your stack to any single two-week window. The teams that quietly run both and route by task type are accumulating an advantage that won’t show up in the convergence cycles — but will compound across them.
The narrative shift is real. It’s just smaller than the takes are pricing it.
For deeper-dive paths: GSD-2 vs Claude Code vs Codex CLI is our long-form harness comparison from earlier this year. Tokenmaxxing covers the YC-operator pattern of running both. Codex Mobile Operator Playbook covers Codex’s mobile angle specifically. And DeepClaude vs Claude Code vs Codex Pro is the cost-stack comparison that started this whole thread.