DeepClaude vs Claude Code vs Codex Pro: 2026 Cost Stack
After DeepSeek V4, the coding-agent stack has three substrates with very different pricing and lock-in. Which should you switch to?

This morning, DeepClaude — a four-line shell shim that points Claude Code at DeepSeek V4 Pro — became the #1 story on Hacker News with 606 points and 257 comments. The second-most-upvoted comment is from someone who cancelled their Claude subscription. The repo’s tagline is “same UX, 17× cheaper.” The agent-loop-vs-model decoupling that vendors have been trying to prevent is now sitting on the front page of the developer internet, and it can be enabled with three export statements.
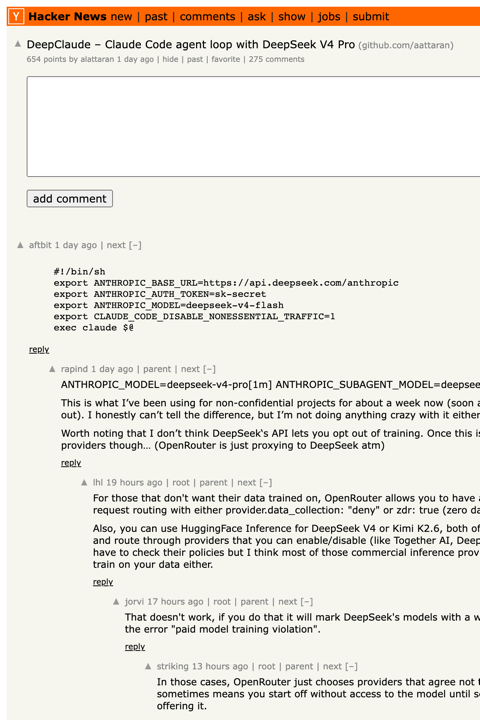
Pair this with two other moves over the last 30 days — Codex Pro’s $200/mo plan now offering 20× the rate limits of ChatGPT Plus, and Anthropic’s continued lock on the “Best Coding AI” Polymarket at 90%+ heading into May resolution — and the question coding-agent buyers are now asking is no longer which model. It’s which substrate — and which one is the right amount of bet to make right now.
This piece is the comparative review. Three substrates: DeepClaude (Claude Code harness on DeepSeek V4 Pro), Claude Code on Anthropic’s API, Codex Pro on GPT-5.4. Same job, three substrates. The cost stack, the quality tradeoff, the latency profile, the lock-in profile, and the harness compatibility — all on the table.
We’re explicitly not declaring a winner. The right answer depends on which constraint binds first for your team. But we will say this: the structural shift implied by DeepClaude is bigger than the cost savings, and we’d argue the contrarian read on the Polymarket odds.
The Three Substrates, Defined
DeepClaude
Claude Code’s harness, swapped to talk to DeepSeek’s Anthropic-compatible endpoint at api.deepseek.com/anthropic. The aattaran/deepclaude repo ships a tiny ~50-line Node proxy plus four export statements. You get every feature of the Claude Code harness — sub-agents, MCP, /resume, hooks, IDE plugins, settings.json — running on DeepSeek V4 Pro at $0.27/M input, $1.10/M output, $0.014/M on cache hits. (Source: DeepSeek pricing.)
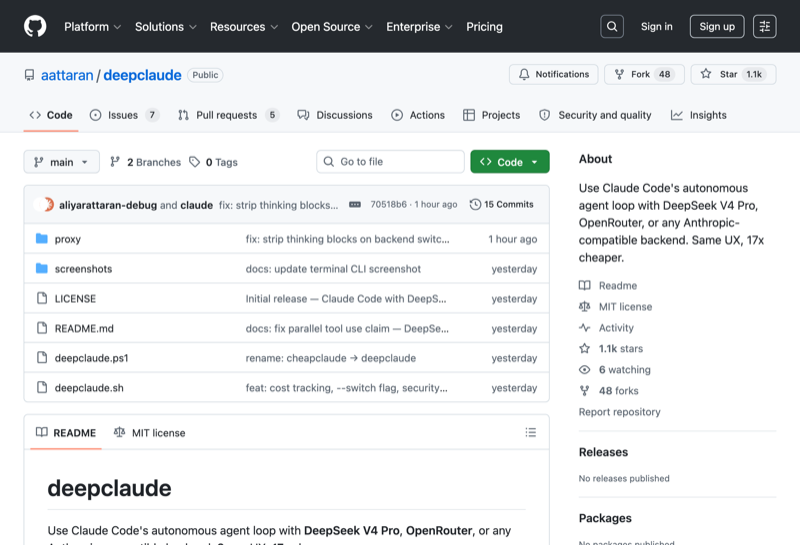
Claude Code (on Anthropic API)
The default. Same harness, same UX, but model calls go to Anthropic’s api.anthropic.com and bill at Sonnet 4.6: $3/M input, $15/M output or Opus 4.7: $15/M input, $75/M output. Quality is the highest of the three substrates on hard tasks — Polymarket has Anthropic at 98.6% to win “Best Coding AI” for April — and the harness has the most mature tooling around it.
Codex Pro (on GPT-5.4)
OpenAI’s substrate. Codex CLI defaults to GPT-5.4, which incorporates GPT-5.3-Codex’s coding capabilities and adds native Computer Use. Subscription plan: $200/mo for 20× ChatGPT Plus limits, with token-based metering as of April 2 2026. The harness pattern is different from Claude Code — Codex leans into cloud-orchestrated long-running agents you supervise from your desktop rather than the local-loop pair-programming model.
The Cost Stack
We modeled three workload profiles across all three substrates, with realistic agent-loop cache hit rates (80%+) where applicable. Token assumptions per session: 50K input, 10K output for the light/medium tier; 150K input, 25K output for heavy.
| Workload | DeepClaude (V4 Pro) | Claude Code (Sonnet 4.6) | Claude Code (Opus 4.7) | Codex Pro (GPT-5.4) |
|---|---|---|---|---|
| Light (5 sessions/day) | $0.18 | $1.50 | $7.25 | $200/mo flat (20× plan) |
| Medium (15 sessions/day) | $0.55 | $4.50 | $22 | $200/mo flat |
| Heavy (40 sessions, longer ctx) | $1.50–3 | $20–40 | $100–200 | API mode: ~$30 |
| Power-user (8h agent loop) | $4–8 | $80–150 | $400–700 | Burns through 20× cap |
Three observations:
1. DeepClaude is structurally cheaper across every workload — not by 2× but by 10–25×. The cache-hit price ($0.014/M) is doing most of the work. In a typical Claude Code session the system prompt + tool definitions + repo context get re-sent every turn, so after the first call you’re spending almost all your input budget at cache rates.
2. Codex Pro’s flat $200/mo with 20× Plus limits is competitive only if your usage is steady-state. Power users hit the 20× cap by mid-month and then degrade to API-mode billing. For irregular bursty workloads the flat rate is excellent value; for sustained heavy use it has a cliff.
3. Claude Opus 4.7 is now ~280× more expensive than DeepSeek V4 Pro on cache hits. That gap is too large to ignore for most workloads even granting Anthropic’s quality lead — which is the part Polymarket’s 98.6% odds aren’t pricing yet.
The Quality Stack
This is the part where the four-line-shim crowd tends to gloss over reality. Same harness does not mean same code quality.
| Benchmark | DeepClaude (V4 Pro) | Claude Sonnet 4.6 | Claude Opus 4.7 | Codex (GPT-5.4) |
|---|---|---|---|---|
| SWE-bench Verified | 80.6 | 76.8 | 80.8 | 79.1 |
| SWE-bench Pro | 55.4 | 58.1 | 64.3 | 60.2 |
| Terminal-Bench 2.0 | 67.9 | 65.4 | 71.2 | 77.3 |
| LiveCodeBench | 93.5 | 88.8 | 91.4 | 90.6 |
| Multi-file refactor (anecdotal) | B | B+ | A | B+ |
(Sources: buildfastwithai V4-Pro review, benchlm.ai, AkitaOnRails benchmarks, Builder.io comparison.)
The honest read:
- For ~80% of normal feature work, DeepClaude is indistinguishable from Sonnet 4.6 and within a hair of Opus 4.7. Single-file edits, narrow refactors, regex, SQL, dependency upgrades — neither is reliably better.
- For multi-file architectural reasoning and long-horizon agent loops that need to recover from their own mistakes, Opus 4.7 still has a real edge. The SWE-bench Pro gap (55.4 vs 64.3) shows up here.
- For terminal-driven workflows (DevOps, CLI tooling, scripts), Codex Pro’s GPT-5.4 leads at 77.3% Terminal-Bench. If your loop is browser- or shell-driven, Codex is measurably better than either Claude or DeepSeek.
- For Computer Use, Claude is the most mature; Codex is catching up; DeepSeek’s tool-call recovery is noticeably worse.
The Lock-In Stack
The lock-in question is what most price comparisons miss. Each substrate locks you in in a different shape.
DeepClaude
Lowest lock-in. Because the entire substrate is “Claude Code’s harness + an env var,” migrating off is also four lines. You can swap to Anthropic’s API by unset-ing three vars. You can swap to OpenRouter by changing the URL. The harness is the constant. Risk: DeepSeek can reprice or restrict the Anthropic-compatible endpoint at any time. They’ve signaled commitment, but it’s a single Chinese company with one endpoint.
Claude Code (Anthropic)
Medium lock-in. Anthropic owns both the harness and the model. They can deprecate or reprice either side. They’ve already done both — the April 4 Max-plan changes cut off third-party tools from the unlimited Max tier; the API is the only escape. The product surface is so good (subagents, MCP, settings.json) that switching costs are real — but DeepClaude shows the harness can run on someone else’s brain, which weakens the long-term lock-in story.
Codex Pro
Highest lock-in. The harness is OpenAI-native. The model is OpenAI-only. The pricing model is plan-tier with token metering. Computer Use is OpenAI’s. Apps SDK distribution lives on ChatGPT. If you build heavily on Codex, you’re committing to OpenAI’s roadmap — and OpenAI has shown more willingness to change pricing and rate limits in-flight than Anthropic.
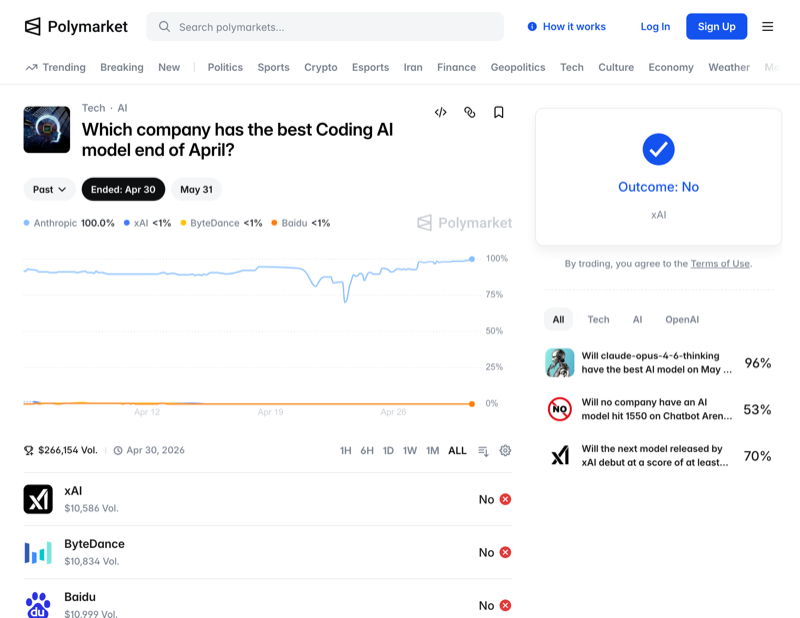
The Polymarket Contrarian Read
Polymarket’s “Best Coding AI” market resolved April at 98.6% Anthropic. The May market currently prices Anthropic at ~77.5%. We think both are mispricing what the substrate decoupling implies.
The market is pricing model quality. But the question developers are actually answering with their wallets — and the question DeepClaude makes inescapable — is not “which model is best on SWE-bench Verified.” It’s “which substrate gives me the best quality-per-dollar-per-month?”
On that metric, Anthropic is not 90%+ likely to win. They might still hold the top of the leaderboard while losing 80% of agent-loop volume to DeepClaude-style swaps. The market is asking the wrong question — or rather, the right question for last year’s stack.
Which Substrate Should You Switch To?
Decision matrix:
| You are… | Substrate to pick |
|---|---|
| Indie dev / startup, cost-sensitive, doing feature work | DeepClaude (test for one week before committing) |
| Enterprise with PRC-data-residency concerns | Claude Code on API or local Ollama |
| Team where Computer Use / browser automation is core | Codex Pro (best agent loop for browser tasks) |
| Architecture-heavy work, multi-file refactors, long-horizon planning | Claude Code on Opus 4.7 — the marginal IQ matters |
| Burst usage (irregular peaks) | Codex Pro (the 20× cap plus flat rate is excellent for spiky load) |
| Steady high-volume production agent | DeepClaude (no rate-limit cliff at scale) |
| You can’t pick one and want optionality | Default to DeepClaude, fall back to Anthropic for hard tasks |
The decoupling means you don’t have to make this a one-substrate decision. You can run DeepClaude as your default and route the hard 20% to Anthropic. The harness is the constant; the brain is the variable.
What Anthropic Does Next
The structural read: Anthropic now has a product (Claude Code) that runs on a competitor’s brain and a competitor’s bill, with Anthropic making nothing on the inference. They have two options:
Option A: tighten the protocol. Make the Claude Code harness phone home for auth in ways that break the env-var swap. This is technically possible but politically expensive — they’d be intentionally degrading developer-favorite tooling to protect inference revenue, and the developer community would notice.
Option B: reprice. Drop Sonnet 4.6 input price by 5–10× to close the gap with DeepSeek. Possible but margin-destructive. Anthropic’s gross margin model assumes high-priced inference.
We’d bet on Option C: reframe the moat as the harness. Sub-agents, MCP, hooks, plugins, IDE integrations, settings.json — that’s the part DeepSeek can’t clone, and Anthropic can keep adding to it. The model becomes a swappable component, but the harness is where value accrues. Polymarket’s “best coding AI” market becomes irrelevant; what matters is “best coding agent.”
That’s also the contrarian read: Anthropic might lose the model-quality lead and still win, because the harness is what developers pay for now.
Bottom Line
If you’ve been reading our Cursor SDK / Browserbase Skills / OpenAI Apps SDK piece from May 2 and our vertical-agent wave coverage from May 3, this is the third substrate-vs-model story in a week. The pattern is unmistakable: the harness is the product, the model is a component, and the price discovery on inference has barely begun.
DeepClaude is the most explicit demonstration of this we’ve seen yet, and the four-line shim is going to drag every other substrate’s pricing toward it. Test it this week. The cost of being wrong is one Saturday afternoon and $5 of DeepSeek credits. The cost of not testing is being on the wrong side of an industry repricing.
Related on AgentConn: