Understand-Anything vs codegraph: Pre-Indexed Graph War
GitHub's #1 and #2 trending repos both pre-index code for AI agents. LLM pipelines + React dashboard vs tree-sitter + MCP. Pick wrong, pay twice.
On May 24, 2026, the top two repos on GitHub Trending are doing the exact same job — pre-indexing source code into a knowledge graph that AI coding agents can query — and they are doing it in completely incompatible ways.
Lum1104/Understand-Anything at #1 with +3,987 stars in 24 hours (24.9K total) ships an LLM-built semantic graph with a React 19 dashboard. colbymchenry/codegraph at #2 with +2,993 stars in 24 hours (21.6K total, day-2 after debuting at #2 yesterday) ships a tree-sitter AST graph in SQLite with an MCP server. The first is for humans who explore code. The second is for agents that query code. Most operator write-ups frame them as competitors. They’re not — they’re two factions of the same architectural bet, and picking the wrong one means paying twice for the index.
Lum1104/Understand-Anything on GitHub →
This is the third consecutive day the agentic substrate consolidation story has surfaced across every intelligence surface we track — eight of fifteen trending repos today are agent tooling, and the convergence report’s HIGH-confidence cluster frames it bluntly: “all model labs are now agent labs.” Underneath, a quieter story is doing structural work: today’s HN front page is led by an Epoch AI piece showing memory is now nearly two-thirds of AI chip cost — with the top comment noting consumer RAM that cost $250 now costs $1,200. When memory becomes the binding constraint, every token an agent doesn’t have to read is money. Pre-indexed graphs aren’t a trend. They’re a hedge.
What they’re optimizing for
Both projects share four primitives — index ahead of time, expose to multiple agents, cut tokens and tool calls, run 100% local. Past those primitives, they diverge cleanly.
Understand-Anything runs a multi-agent LLM pipeline at index time. Five agents in sequence — project scanner, file analyzers (up to three concurrent), graph builder, summarizer, persona-tagger — scan the repo, extract files/functions/classes/dependencies, then emit a plain JSON file at .understand-anything/knowledge-graph.json and launch a local React 19 dashboard with React Flow + Dagre layout. Each node carries a plain-English summary the LLM wrote during indexing. The dashboard adds fuzzy + semantic search, guided tours, diff-impact analysis, and a persona-adaptive UI that toggles detail level between junior dev / PM / senior engineer.
codegraph runs a deterministic tree-sitter parser at index time. It extracts symbols, edges, call graphs, and file relationships into a SQLite FTS5 store across 16+ languages — no LLM call required. It then exposes the graph as an MCP server that Claude Code, Codex CLI, Cursor, OpenCode, and Hermes Agent connect to natively. Across seven open-source codebases, it averages 35% cost reduction, 59% fewer tokens, 49% faster responses, 70% fewer tool calls — and on large repos the agent often answers from the index in a handful of MCP calls with zero raw file reads.
colbymchenry/codegraph on GitHub →
The split is structural, not stylistic. Understand-Anything’s nodes carry meaning; codegraph’s nodes carry structure. The same function appears in both graphs, but Understand-Anything writes “handles Stripe webhook idempotency for subscription renewals” and codegraph writes payment.webhooks.handle_renewal(event: StripeEvent) -> Result<()> with edges to its callers, its tests, and the queue it dispatches to. One is for the human who needs to understand; the other is for the agent that needs to query.
💡 The architectural fork in one sentence. Understand-Anything optimizes for the operator question “how does this work?” — answered once, in English, at index time. codegraph optimizes for the agent question “which symbol calls X?” — answered on demand, in SQL, every time the agent reasons.
The index economics nobody is pricing in
Indexing is not free, and the difference is enormous.
Understand-Anything’s five-agent pipeline runs LLM calls over every file in the repo. Operator reports on the community walkthroughs put indexing cost at $2–10 for medium repos and $20–50 for large monorepos, plus 10–30 minutes wall-clock per index pass. Re-indexing on every meaningful diff is impractical, which is why the project emphasizes the JSON-commit pattern: index once, commit the graph, teammates skip the pipeline.
codegraph’s tree-sitter pipeline runs in seconds-to-minutes locally for the same repos, with zero LLM cost at index time. Re-indexing on every commit is so cheap it’s the default — the docs suggest a git hook. The trade is that codegraph’s graph is structurally correct but semantically opaque; nothing in the SQLite store can answer “how does this work?” without an LLM round-trip on read.
That difference compounds with today’s macro picture. The Epoch AI memory-cost piece on HN makes the case that memory has grown to two-thirds of AI chip component cost; Simon Willison amplified David Oks on the consumer-electronics repricing alongside it. When an Explore agent reads 20–50 files per question and memory is the binding cost, the 94% resource reduction reported by similar pre-indexing MCPs isn’t a nice-to-have — it’s the inference-economics hedge for every coding agent operator in 2026.
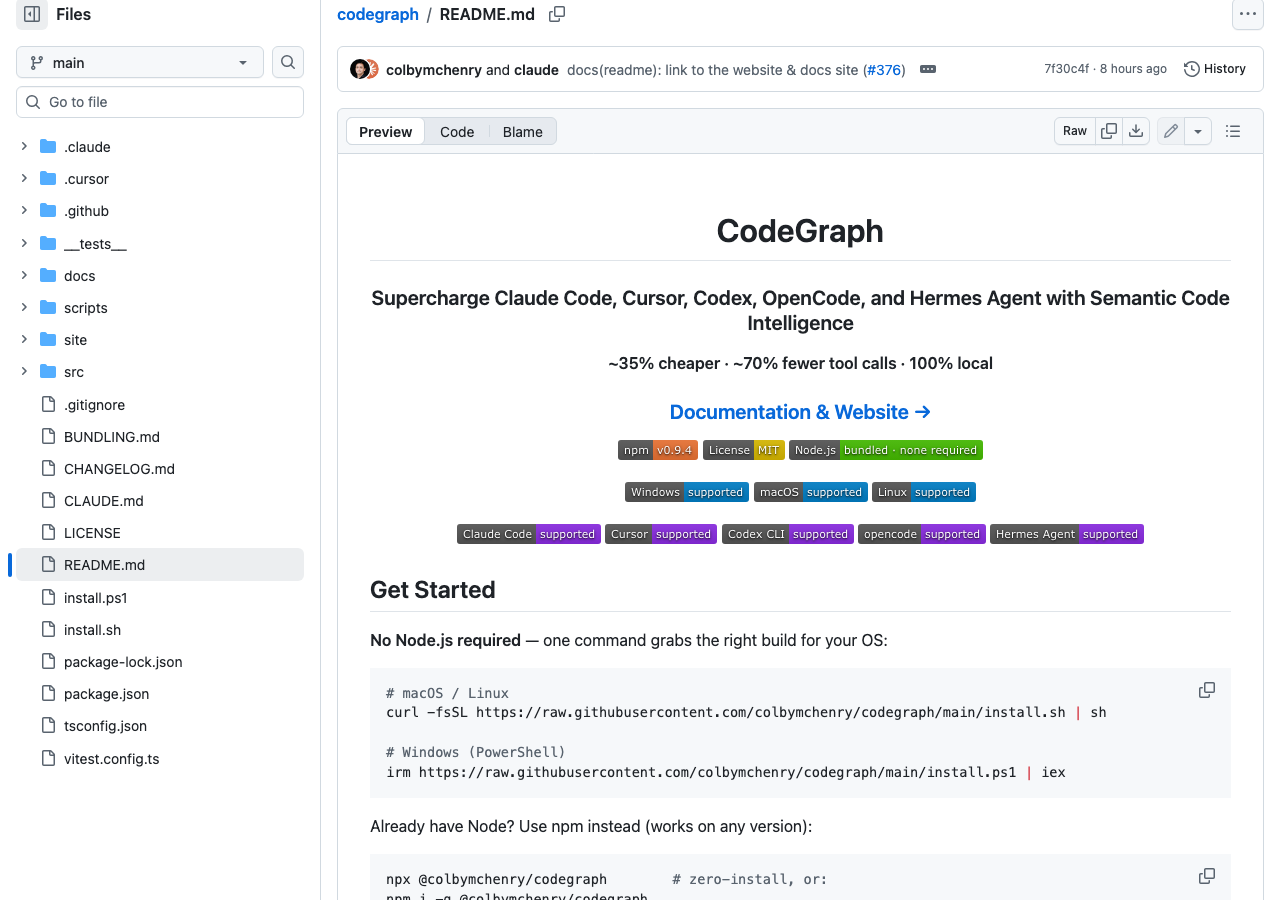
codegraph benchmarks (README) →
The economically defensible split looks like this: pay Understand-Anything’s index cost once per major release branch to get a teaching artifact teammates and PMs can read; let codegraph reindex every commit as the agent’s working memory. They sit on top of the same repo at the same time. That’s not a competition — that’s a stack.
Where each one wins
The naive operator question is “which one should I install?” The accurate operator question is “which question am I trying to answer?”
Use Understand-Anything when the consumer is human. Onboarding a new engineer to a legacy monorepo. A PM asking “how does our auth flow work?” without having to read a single line of TypeScript. A senior engineer doing diff-impact analysis before a risky refactor. The plain-English summaries and the guided tours are the product; the React dashboard is the interface; the LLM cost is the price of teaching. Independent walkthroughs from ddewhurst and Better Stack both anchor on the same use case: it’s a teaching artifact, not a query layer.
Use codegraph when the consumer is an agent. Claude Code working through a 50-file refactor. Codex CLI auditing call sites before a breaking change. Cursor jumping to the actual implementation through three indirection layers. OpenCode answering “which test files cover this module?” The MCP integration is the product; the SQLite store is the interface; the tree-sitter determinism is the price of correctness. AIToolly’s launch coverage frames it directly: “on large repos the agent answers from the index in a handful of calls with zero file reads, while the no-CodeGraph agent fans out across grep/find/Read.”
🔧 Decision rule for operators. If your agent’s loop is grep/find/Read-heavy, install codegraph and watch the tool-call counter drop ~70%. If your team’s onboarding doc is a Notion page nobody updates, run Understand-Anything once, commit the JSON, and treat the dashboard as the doc.
What about Claude Code specifically
Both projects target Claude Code as their primary platform, but they integrate at different layers, and the integration cost is asymmetric.
codegraph plugs into Claude Code as an MCP server. Install once via npx @colbymchenry/codegraph install and the interactive installer registers the MCP server in ~/.claude/mcp.json. Claude Code sees a new set of tools — code_search, find_callers, get_symbol_definition, list_dependents — and uses them whenever the user prompts it to “find” or “trace” something. The same install also wires up Codex CLI, Cursor (via cursor.json), OpenCode, and Hermes. One install, five agents, zero per-agent configuration.
Understand-Anything ships as a Claude Code plugin. It runs as a slash-command pipeline — /understand-anything triggers the multi-agent indexer, opens the dashboard, and writes the JSON to the repo. Claude Code can read the JSON afterward, but the integration is via the file (in-context JSON), not via tool calls. The dashboard is the primary surface. For Codex / Cursor / Copilot / Gemini CLI, the integration is “read the committed JSON” — which works, but isn’t bidirectional and doesn’t give the agent a query interface beyond a file dump.
This is where yesterday’s codegraph piece on AgentConn understated the comparison. We framed codegraph as “the missing knowledge graph for 5 coding agents” — accurate, but Understand-Anything is solving a different problem at the same layer, and the harness-layer story now has two competing primitives that should coexist in the same install.
The broader substrate war
The reason these two repos are #1 and #2 the same day isn’t coincidence — it’s the same dynamic Latent Space named in “All Model Labs are Now Agent Labs” playing out at the harness layer. Today’s GitHub Trending top ten also includes andrej-karpathy-skills at #3 (+2,555 stars), cc-switch (multi-agent CLI panel), chrome-devtools-mcp, and dexter. Eight of fifteen are agent tooling.
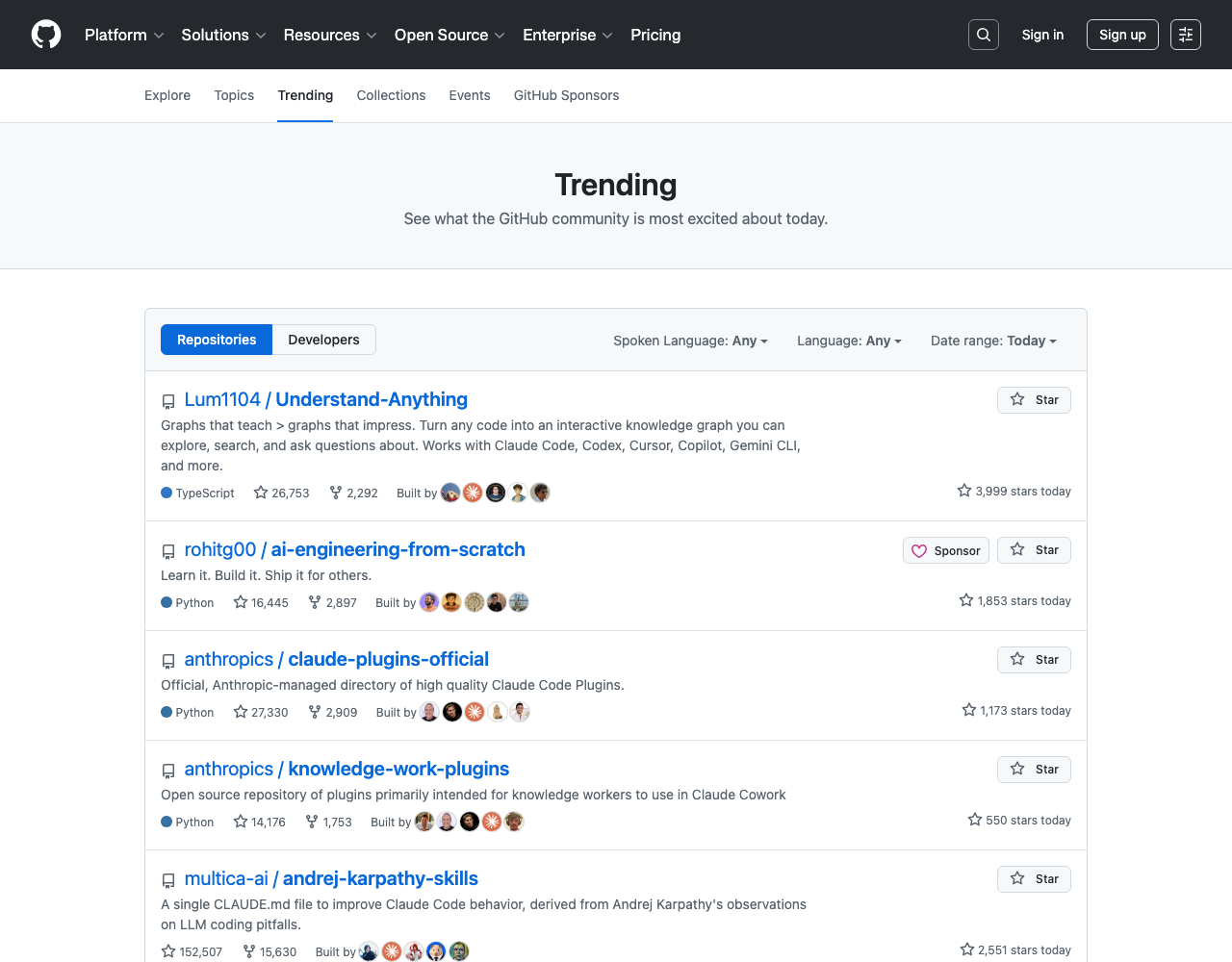
GitHub Trending — 2026-05-24 snapshot →
The pattern is consistent: operators are reaching for more structured primitives at every layer beneath the agent’s reasoning loop. Pre-indexed retrieval at the codebase layer (codegraph, Understand-Anything), vectorless tree-search at the document layer, skill-derived prompt primitives at the policy layer (karpathy-skills, obra/superpowers), and harness-level switching at the front (cc-switch). The model itself is increasingly the cheapest, most fungible piece of the stack — Anthropic’s June Polymarket dominance (76% Best, 76% Second, 62% Third) confirms the substrate is where the differentiation is moving.
⚠️ The trap operators are falling into. Treating Understand-Anything and codegraph as “either/or” because they’re both #1/#2 on the same day. They optimize for different consumers. Operators who install only one of them are either burning tokens on agent queries (Understand-Anything alone) or leaving the human-side onboarding cost on the floor (codegraph alone). The defensible install today is both, with codegraph’s MCP wired to the agents and Understand-Anything’s dashboard wired to the team.
What we’re watching next
Three forks worth watching from here. First, whether Understand-Anything ships an MCP server — that would collapse the operator decision back into “pick one.” There’s nothing in the current README suggesting it’s planned, but the demand signal is loud. Second, whether codegraph adds LLM-summarized layers behind a flag — turning its deterministic graph into a teaching artifact on read. The architecture supports it; the founder’s positioning (“100% local, zero LLM cost”) suggests it won’t. Third, whether a third repo lands that does both — tokensave is already a candidate at 40+ tools across 30+ languages with both structural and semantic layers, but hasn’t hit trending velocity yet.
The harness-layer fork is real, the economic motivation is real, and the operator decision is now binary in the wrong way. The right reading of today’s trending page isn’t “which knowledge graph won” — it’s “the substrate just split into two factions, and the stack needs both.”
If you’re picking exactly one today, pick by consumer. If your agent is reading more than your team is, install codegraph. If your team’s onboarding pain is louder than your agent’s token bill, install Understand-Anything. If both are loud — and for any team running Claude Code or Codex CLI at scale in 2026, they are — install both, commit the Understand-Anything JSON, and wire the codegraph MCP. Pay each index cost once. Stop paying the no-index cost forever.