codegraph: The Missing Knowledge Graph for 5 Coding Agents
codegraph hit GitHub #2 on day one — a local knowledge graph that cuts Claude Code, Codex, Cursor, OpenCode, and Hermes token spend by 59%.
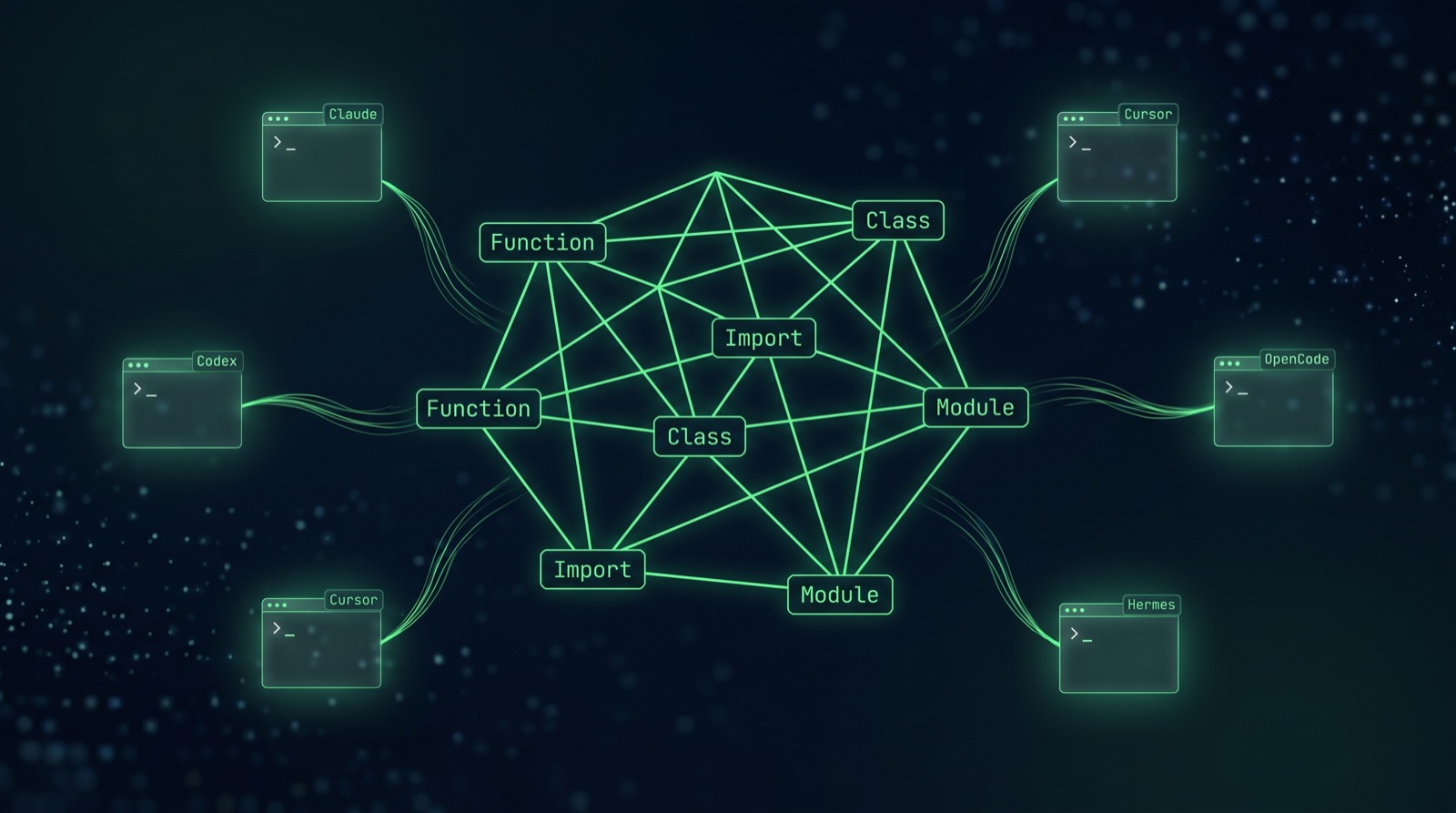
colbymchenry/codegraph added 2,434 stars in 24 hours and rocketed to #2 on GitHub Trending on May 23. It’s a local-first, multi-agent code knowledge graph — built specifically for Claude Code, Codex CLI, Cursor, OpenCode, and Hermes Agent — with median benchmarks of 59% fewer tokens, 49% faster responses, and 70% fewer tool calls across seven real-world codebases.
That ranking matters because of the company it’s keeping. The same trending day, multica-ai/andrej-karpathy-skills gained 3,372 stars at #1, Lum1104/Understand-Anything gained 2,331 stars at #3 with the same knowledge-graph thesis, and NousResearch/hermes-agent gained 1,334 stars — the agent codegraph integrates with. Five of the day’s top ten trending repos are coding-agent infrastructure. Latent Space’s “All Model Labs Are Agent Labs” thesis isn’t a forecast anymore; it’s the trending page.
This article unpacks what codegraph actually does, where it sits in the agent stack, and why a pre-indexed knowledge graph is the missing primitive for the entire multi-agent coding landscape — not just one tool.
What codegraph Actually Builds
The core idea is straightforward but underappreciated: most coding agents waste 60–70% of their tokens re-discovering code structure on every task. When you ask Claude Code to “refactor parseConfig to support YAML,” the agent typically reads 5–15 files, runs grep on a few symbols, traces a couple of imports, then writes the actual change. That exploration is repeated every time — there’s no persistent memory of the codebase shape.
codegraph replaces that with a one-time, local indexing pass:
The pipeline: Tree-sitter parses source → language-specific queries extract nodes (functions, classes, files) and edges (calls, imports, inheritance) → SQLite (
.codegraph/codegraph.db) stores it with FTS5 full-text search → post-extraction reference resolution links calls to definitions → native OS file watchers (FSEvents/inotify/ReadDirectoryChangesW) keep it current with 2-second debouncing.
The agent doesn’t read files to understand structure; it queries the graph. The graph already knows parseConfig is called by 3 callers, that it imports from ./yaml-utils.ts, and that its definition lives at src/config/parser.ts:147. The agent reads only the file it’s editing.
The MCP Surface — Why Multi-Agent Works
codegraph exposes itself as an MCP server with nine tools. That’s the architectural choice that lets it serve five agents from one index:
| Tool | What it returns |
|---|---|
codegraph_search | Symbol lookup (function, class, variable) |
codegraph_context | Task-relevant code gathered semantically |
codegraph_callers / codegraph_callees | Call-graph traversal |
codegraph_impact | Change-blast-radius analysis |
codegraph_explore | Multi-file source retrieval |
codegraph_node | Symbol details (signature, doc, location) |
codegraph_files | Indexed structure overview |
codegraph_status | Index health |
Because the surface is MCP, the same .codegraph/codegraph.db works for any agent that speaks the protocol. Today that’s Claude Code, Codex CLI, Cursor, OpenCode, and Hermes Agent — five distinct harnesses with five different cost-token economics. None of them have to ship their own indexer. None of them have to re-invent semantic exploration. Switch agents, keep the graph.
This is exactly the substrate pattern we covered in our analysis of cursor-skills-as-runtime: increasingly, the agent harnesses commoditize, and the infrastructure beneath them — skills, MCP servers, knowledge graphs — is where the moats are quietly forming.
The Swift Compiler Benchmark
The most-quoted figure in codegraph’s README is the Swift Compiler benchmark: 25,874 files, 272,898 nodes, indexed in under 4 minutes. On a complex question against that index, an agent answered with 6 explore calls and zero file reads in 35 seconds.
That number deserves to be sat with. The Swift Compiler is one of the largest open-source C++ codebases in active development. The same question through a vanilla Claude Code session would routinely take 90–180 seconds, 25–40 tool calls, and 200K–400K tokens of context. codegraph compresses it to a half-minute conversation that fits in the agent’s context window without truncation.
Across the broader seven-codebase test suite, the median compression is the marketing line: 35% cheaper, 59% fewer tokens, 49% faster, 70% fewer tool calls. Even discounting these numbers heavily — vendor benchmarks are vendor benchmarks — the order of magnitude is right. Pre-indexed semantic data beats just-in-time grep + read for the same reason database indexes beat full table scans.
The Parallel Implementations Tell the Real Story
If codegraph were a one-off, the trending page would have one knowledge-graph tool. It has at least three:
- codegraph (#2, 2,434 stars/day): MCP server, multi-agent, SQLite + FTS5
- Understand-Anything (#3, 2,331 stars/day): “Turn any code into an interactive knowledge graph you can explore and query”
- code-review-graph by tirth8205: “6.8× fewer tokens on reviews and up to 49× on daily coding tasks”
Three independent implementations of the same primitive shipped within the same trending window. That’s the signal. The agent ecosystem has collectively discovered that the bottleneck on coding agents stopped being model capability and became context efficiency, and that pre-indexing is the obvious answer.
It’s the same lesson search engines learned in 1998: you can re-grep the web on every query, or you can build an inverted index and query it. The cost difference is several orders of magnitude. Coding agents are running their 1995 phase right now — re-grepping the codebase per task. codegraph and its peers are the inverted index.
Where codegraph Sits in the Multi-Agent Stack
For AgentConn readers building production agent setups, the practical positioning question is: does codegraph belong in your stack? The honest answer depends on three variables:
1. Codebase size. Under 1,000 files, the indexing overhead and graph maintenance cost out-weigh the savings. Claude Code’s built-in tooling handles small repos cleanly. Above ~5,000 files, codegraph starts winning material money. Above 25,000 files (think Swift compiler, Chromium subtree, large monorepos), it’s not optional.
2. Multi-agent reality. If you’re firmly committed to one agent, the case is weaker — that agent’s vendor will eventually ship its own indexer. But if you’re running cc-switch style multi-agent workflows or evaluating Codex pulling ahead of Claude Code, one shared index across agents is the architectural win. You don’t re-index when you switch.
5. Privacy posture. codegraph is 100% local. No cloud round-trips, no embeddings sent to an external service, no telemetry. For enterprise codebases under NDA or regulatory constraint, that’s not a feature — it’s a requirement. Most “code RAG” alternatives can’t say the same.
What’s Still Missing
codegraph nails the indexing-and-query layer. It doesn’t (yet) solve:
- Semantic-versioning of the graph. What does the graph look like at commit
abc123vs.def456? Useful for code review agents reasoning about diffs against historical state. - Cross-repo graphs. If your project depends on three internal packages, you want all three indexed and linked. Today, each repo is an island.
- Concept-level edges. Tree-sitter gives you syntactic edges (this function calls that function). It doesn’t give you semantic ones (this function is a cache invalidator for that store). Those edges have to come from somewhere — either LLM-extracted post-processing or developer annotation. Neither is in codegraph today.
These are the next 12 months of the category, not codegraph’s failings. The fact that codegraph shipped the useful 80% in v1 is why it’s at #2.
The Buy/Build/Wait Read
Two questions matter:
Should you adopt codegraph today? If your codebase is over 5,000 files and you’re already paying Claude Code or Codex bills above $200/month per developer, yes. The 59% token reduction more than pays for the half-day setup. Install via npx @colbymchenry/codegraph and codegraph init -i in your project root.
Should you bet on the category? Yes, but loosely. codegraph could be the winner, Understand-Anything could be, or — more likely — Anthropic, OpenAI, and Cursor will each ship their own native indexer in the next 6 months and the standalone tools will get squeezed. The MCP-based ones (codegraph) have a path to surviving that squeeze: even if Claude Code ships its own indexer, codegraph’s MCP server stays useful when you switch to Codex.
The deeper bet — that something like a pre-indexed code knowledge graph becomes table stakes for serious coding agents in 2026 — is the safe one. Three independent implementations on GitHub Trending in the same week is the market making that call out loud.
How AgentConn Will Track This
We’ve added codegraph, andrej-karpathy-skills, and oh-my-pi to the AgentConn directory and refreshed trending-repos.json with today’s velocities. The “knowledge-graph for coding agents” tag joins our existing harness-substrate coverage so you can compare codegraph against Understand-Anything, code-review-graph, and the inevitable wave of Anthropic-native and OpenAI-native indexers as they ship.
If you’re building production agent setups and want this category’s evolution surfaced in one feed, watch the Coding directory — that’s where the next two quarters of this story will land.