headroom: Cut Agent Token Costs 60–95%
headroom compresses tool outputs, logs, and RAG chunks before they reach the LLM. Library, proxy, or MCP server. Here's the operator setup.
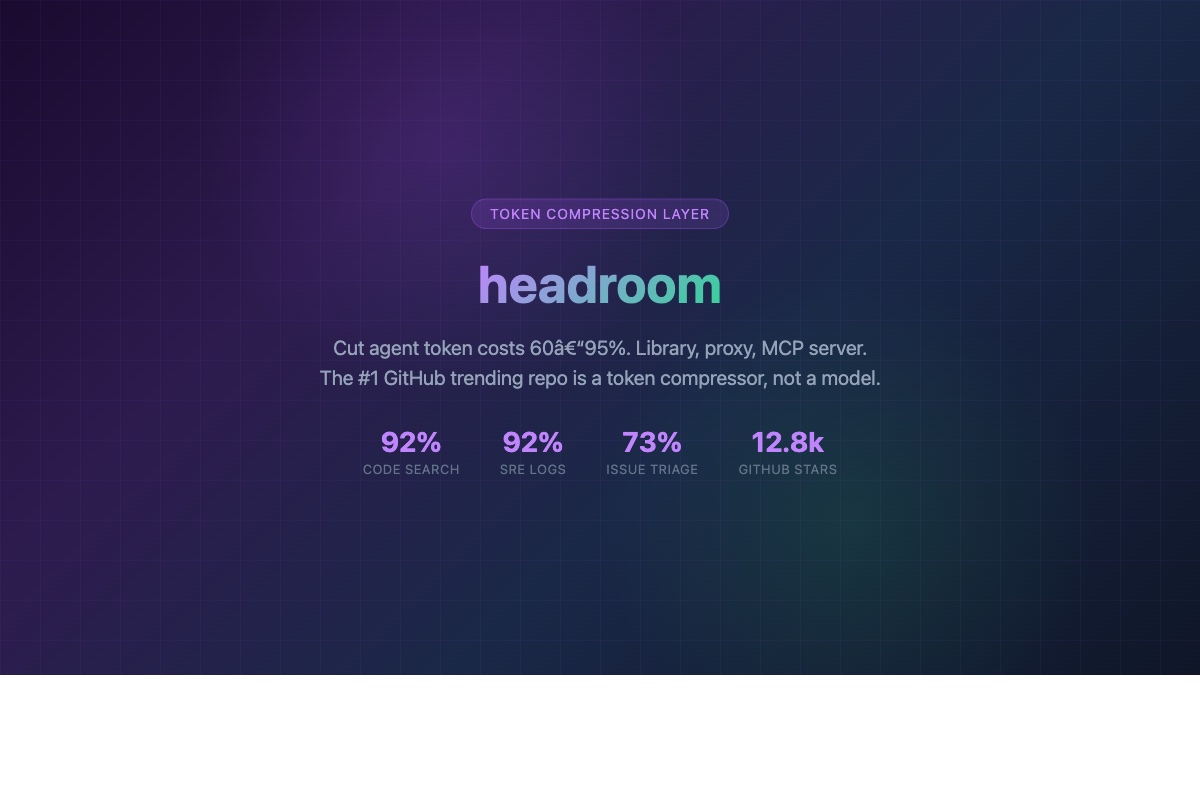
The #1 trending GitHub repo by velocity this week isn’t a model, a framework, or an agent harness. It’s a token compressor. headroom hit 12.8k stars at +3,139 per day — and the timing tells you everything about where the AI agent market is right now.
Uber just burned through its entire 2026 AI coding budget in four months and capped engineers at $1,500/month per tool. Roughly 5,000 engineers, monthly bills between $150 and $2,000 each. The problem isn’t adoption — it’s that tool outputs, logs, and search results bloat the context with every turn. By turn 10 in an agent conversation, you’re paying for 100k+ tokens on every LLM call.
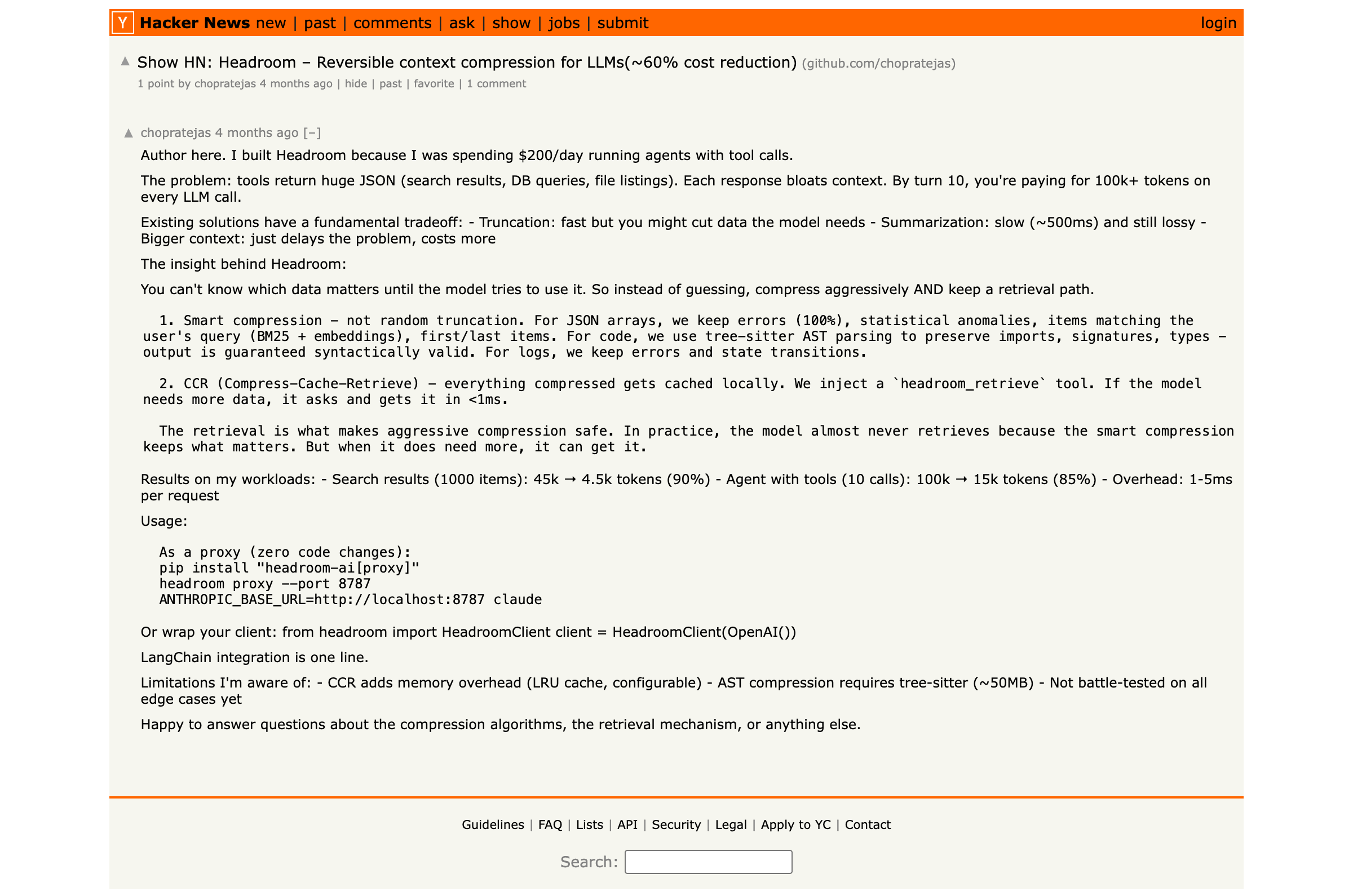
headroom compresses everything your agent reads — tool outputs, logs, files, RAG chunks — before it reaches the LLM. Built by Tejas Chopra, a senior Netflix engineer, the tool claims 60–95% fewer tokens with the same answers. Early adopters report $700K in cost savings and 200 billion tokens freed.
This is an operator how-to. We’ll cover what headroom does, the three install modes, realistic savings expectations, and where compression costs you accuracy.
What headroom Actually Does
headroom sits between your agent’s orchestrator and the LLM API. It intercepts outbound context — tool results, file contents, conversation history — and compresses it before the model sees it. The compressed output preserves the semantic content the model needs while stripping noise, redundancy, and structural bloat.
Three compression strategies power it:
SmartCrusher handles JSON. Most tool outputs return arrays of objects — search results, database rows, API responses. SmartCrusher extracts representative samples, deduplicates repeated structures, and strips fields the model doesn’t need for the current task. It’s deterministic and schema-preserving: the model gets a valid JSON subset, not an invented summary.
CodeCompressor is AST-aware for Python, JavaScript, Go, Rust, Java, and C++. Instead of treating code as raw text, it parses the syntax tree and compresses based on structural patterns — import blocks, boilerplate signatures, repetitive test scaffolding. This is the strategy that delivers the highest compression on code search results.
Kompress-base is a custom HuggingFace model trained on agentic traces. For prose, documentation, and mixed content that doesn’t fit the JSON or code pipelines, Kompress handles the compression with a learned model that understands what agents typically need from unstructured text.
The routing is automatic: a ContentRouter detects the content type and sends it to the right compressor. A CacheAligner runs first to stabilize request prefixes — this matters because Anthropic and OpenAI’s KV caches only hit when the prefix is identical. Compression that changes the prefix layout on every call kills your cache hit rate. CacheAligner prevents that.
The Three Install Modes
headroom ships as a Python library (pip install "headroom-ai[all]"), a Node package (npm install headroom-ai), and three deployment modes.
1. Library — Inline Compression
Wrap your agent’s messages before sending them to the API:
from headroom import compress
compressed = compress(messages)
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=compressed
)Best for: Custom agent code where you control the API call. Lowest latency — no network hop.
2. Proxy — Zero Code Changes
Start the proxy and point your agent’s base URL at it:
headroom proxy --port 8787
export ANTHROPIC_BASE_URL=http://localhost:8787/v1Your agent talks to the proxy instead of the API directly. headroom compresses on the fly, forwards to the real API, and returns the response. No code changes needed.
Best for: Wrapping existing agents. headroom-desktop ships this as a Mac app that claims “2x more Claude Code usage” by compressing context before it hits your rate limit.
3. MCP Server — Agent-Controlled Compression
headroom exposes three MCP tools: headroom_compress, headroom_retrieve, and headroom_stats. The agent calls them as needed — compress before a long context pass, retrieve originals when it needs the full document, check stats to monitor savings.
headroom mcp --port 3333Best for: Agent frameworks with MCP support (Claude Code, Codex, OpenClaw). The agent decides when to compress, which gives it control over the accuracy/cost tradeoff.
Real-World Token Savings
From the official benchmarks:
| Scenario | Before | After | Savings |
|---|---|---|---|
| Code search (100 results) | 17,765 tokens | 1,408 tokens | 92% |
| SRE incident debugging | 65,694 tokens | 5,118 tokens | 92% |
| GitHub issue triage | 54,174 tokens | 14,761 tokens | 73% |
The pattern: structured, repetitive content (JSON arrays, log lines, search results) compresses the most. Mixed-content scenarios like issue triage compress less because there’s more unique prose.
Put that in dollar terms. If your agent runs 50 coding sessions per day at an average of 100k tokens per session, and headroom compresses 80% of that context, you’re saving ~4M tokens daily. At Claude Sonnet’s input pricing ($3/M tokens), that’s $12/day or $360/month per developer. Across a 50-person team, headroom could save $18,000/month — real money, and exactly the kind of cost that made Uber impose a cap.
When Compression Costs You Accuracy
This is the section most coverage skips. headroom’s benchmark results look excellent:
| Benchmark | Category | Baseline | With Headroom | Delta |
|---|---|---|---|---|
| GSM8K | Math | 0.870 | 0.870 | ±0.000 |
| TruthfulQA | Factual | 0.530 | 0.560 | +0.030 |
| SQuAD v2 | QA | — | 97% accuracy | 19% compression |
| BFCL | Tools | — | 97% accuracy | 32% compression |
The GSM8K result is encouraging — zero accuracy loss on math reasoning. TruthfulQA actually improves slightly, suggesting compression strips noise that was confusing the model.
But the caveats matter:
Schema-sensitive tasks. If your agent processes API responses where field names or nested structures carry semantic meaning, SmartCrusher’s field-stripping can remove information the model needs. Test on your actual tool outputs, not generic benchmarks.
Long-range code dependencies. CodeCompressor works at the file level. If your agent needs to reason about cross-file imports or long call chains, aggressive compression of individual files can break the reasoning chain. The CCR (Content-Compressed Retrieval) mode helps — it stores originals locally and lets the model fetch full documents on demand — but adds a retrieval round-trip.
Low-redundancy content. Compression ratios drop sharply when the input is already dense. A carefully written specification or a short, unique error message won’t compress well. headroom’s ContentRouter handles this gracefully (it passes low-redundancy content through with minimal changes), but don’t expect 90% savings on every input.
The honest framing: headroom works best on the fat tail of agent context — large tool outputs, verbose logs, repetitive search results. That’s where most of your token spend goes anyway. On dense, unique, semantically rich content, compression savings are modest and the accuracy risk is higher.
Where It Fits in a Claude Code / Codex Stack
For Claude Code users, the proxy mode is the path of least resistance:
pip install "headroom-ai[all]"
headroom proxy --port 8787Then set ANTHROPIC_BASE_URL=http://localhost:8787/v1 in your environment. Claude Code routes all API calls through headroom automatically.
For Codex, the same proxy approach works — point OPENAI_BASE_URL at the proxy.
For multi-agent setups, headroom supports shared context — compressed context can be passed between agents with provenance tracking, so agent B knows which agent A produced a given compressed chunk.
The Market Signal
The fact that the #1 trending GitHub repo is a token compressor, not a model or a harness, tells you where the cycle is. The adoption phase is over. Engineers have the tools. Now they’re staring at the bill.
Uber’s $1,500/month cap is the headline, but the structural dynamic is broader. Every company that rolled out Claude Code or Codex to engineering teams in late 2025 is hitting the same inflection: usage rates between 84% and 95%, per-engineer costs that nobody budgeted for, and a finance team asking hard questions.
headroom is the practitioner-side response to that pressure. It doesn’t make the model cheaper — it makes you use the model less. And when the hottest open-source project in the ecosystem is “how to consume fewer tokens,” the subsidy era’s expiration date just became visible.
Getting Started
Install and run the proxy in two commands:
pip install "headroom-ai[all]"
headroom proxy --port 8787For the MCP server:
headroom mcp --port 3333For the full documentation, benchmarks, and integration guides: chopratejas.github.io/headroom
The code is Apache 2.0 licensed. It supports Python 3.10+ and Node.js. If you’re running a coding agent stack and haven’t profiled your token spend yet, headroom is the tool that makes the invisible cost visible — and then cuts it.
headroom is listed in the AgentConn directory. For related agent cost analysis, see our agent observability and usage tracking guide and tokenmaxxing operator pattern.