Field report · · AgentConn Team
Agent Observability Is the Next Battleground
Microsoft pulled Claude Code over budget overruns. Anthropic shipped /usage the same week. Whoever owns the agent observability layer wins.
In a single week in May 2026, three things happened that look unrelated and aren’t. Microsoft yanked Claude Code from an internal deployment, citing budget overruns — the #1 AI-tagged story on Hacker News for the day. Anthropic shipped /usage inside Claude Code, a per-Skill / per-Agent / per-MCP / per-Plugin token-spend dashboard. OpenAI dropped four Codex updates in one ship, including long-running goals and shareable team plugins. Superset launched on Hacker News pitched as “the IDE for the agents era.” GitHub trending was top-to-bottom coding agents — opencode at #2 overall, plus openai/codex, hermes-agent, oh-my-pi, multica-ai, dotnet/skills.
The pattern across the news cycle has nothing to do with model capability. The race has shifted. The next 90 days of agent competition will be fought on observability and governance, not benchmarks. Whoever owns the dashboard that proves agent spend is bounded — to a CFO, to an enterprise procurement function, to a developer who can’t justify a $4,000 monthly Claude Code bill to their VP of Engineering — wins the platform layer for the rest of the cycle.
This piece does three things. First, frame the Microsoft / /usage / Codex convergence as a single market-structure event, not three news items. Second, map the agent observability stack — the five primitives every serious player is now shipping. Third, identify which vendor is positioned to win and which is positioned to be acquired by the end of the year.
1. One news cycle, three governance signals
Read the week’s news in order, not in isolation:
- HN #1 AI story: Microsoft pulled Claude Code from an internal deployment over budget overruns.
- Chamath response: “The issue isn’t that the tool isn’t useful. The issue is that without context and oversight, the tool can spin forever and burn budget — Microsoft pulling Claude is the first, but not the last.”
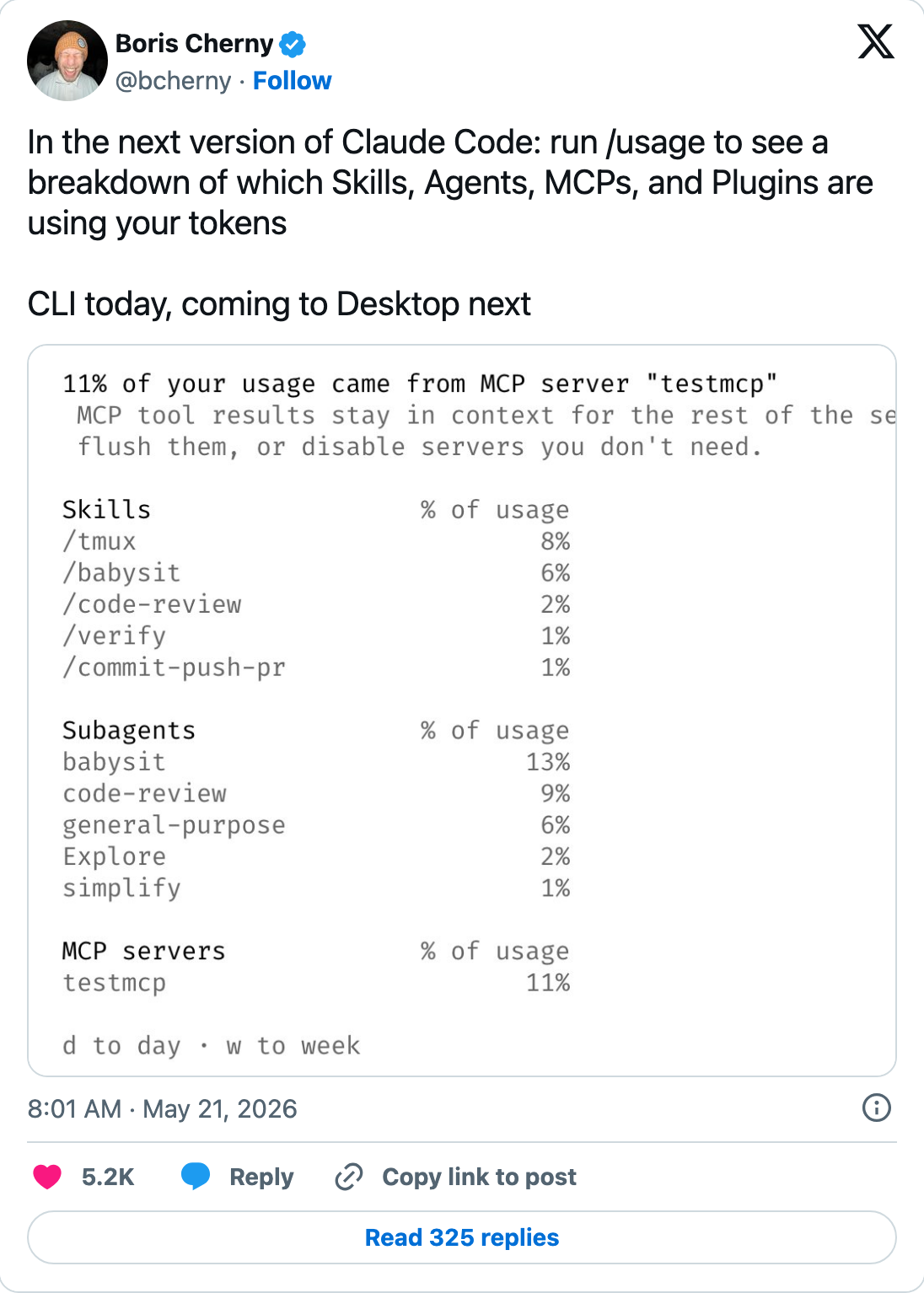
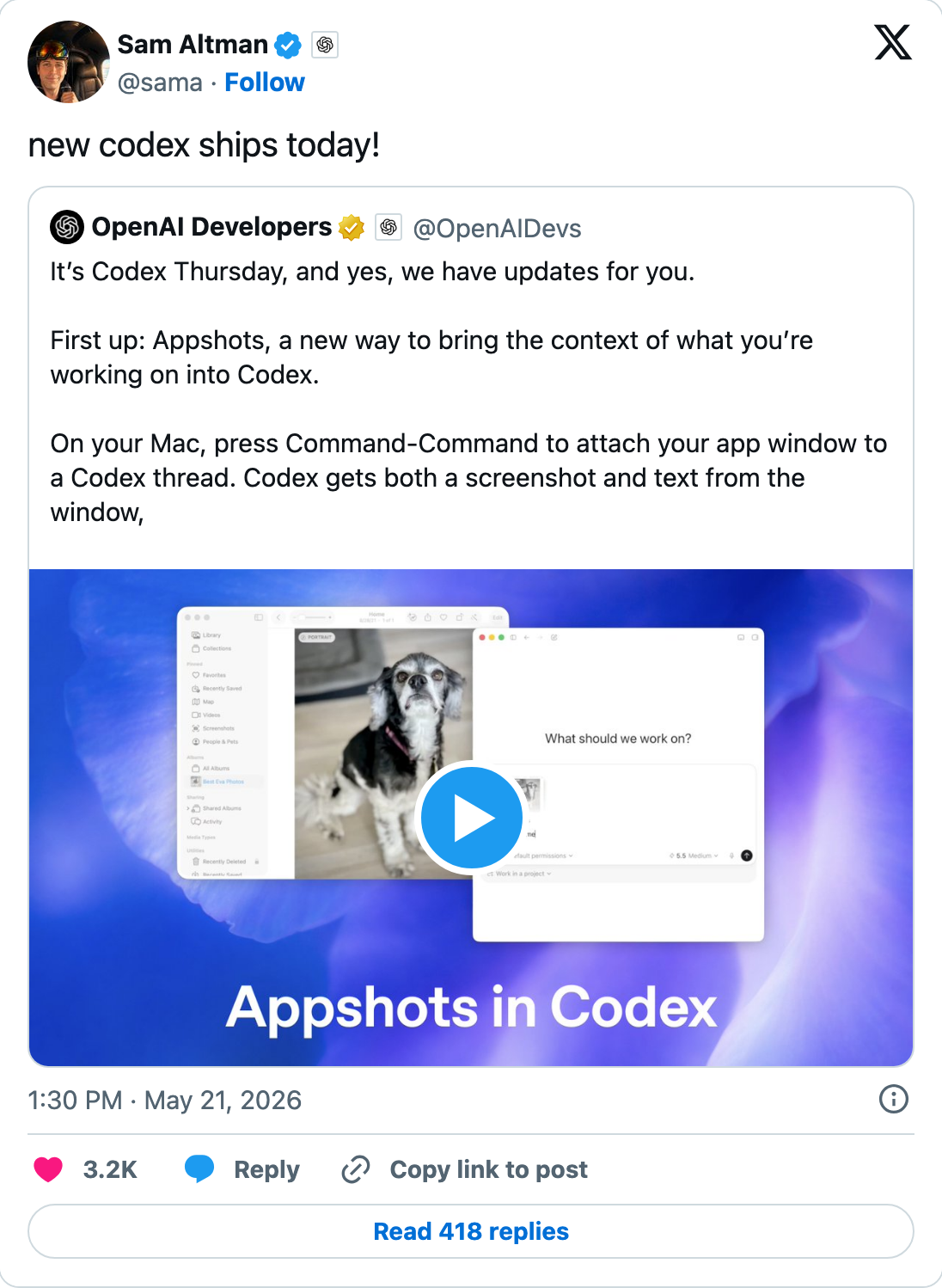
- Anthropic ship: bcherny announces
/usagein Claude Code — token spend broken down by Skill, Agent, MCP, and Plugin. Source - OpenAI ship: sama announces four simultaneous Codex updates — long-running goals, shareable team plugins, Appshots, and a Cisco case study. Source
- HN #3 launch: Superset — “IDE for the agents era.” Positions itself as the cockpit, not the agent.
- Skeptic counter: jeremyphoward, retweeting an engineer claim that “these engineers can review their agent’s code much faster than reviewing human code,” replies “wat” — the mainstream-skepticism marker.
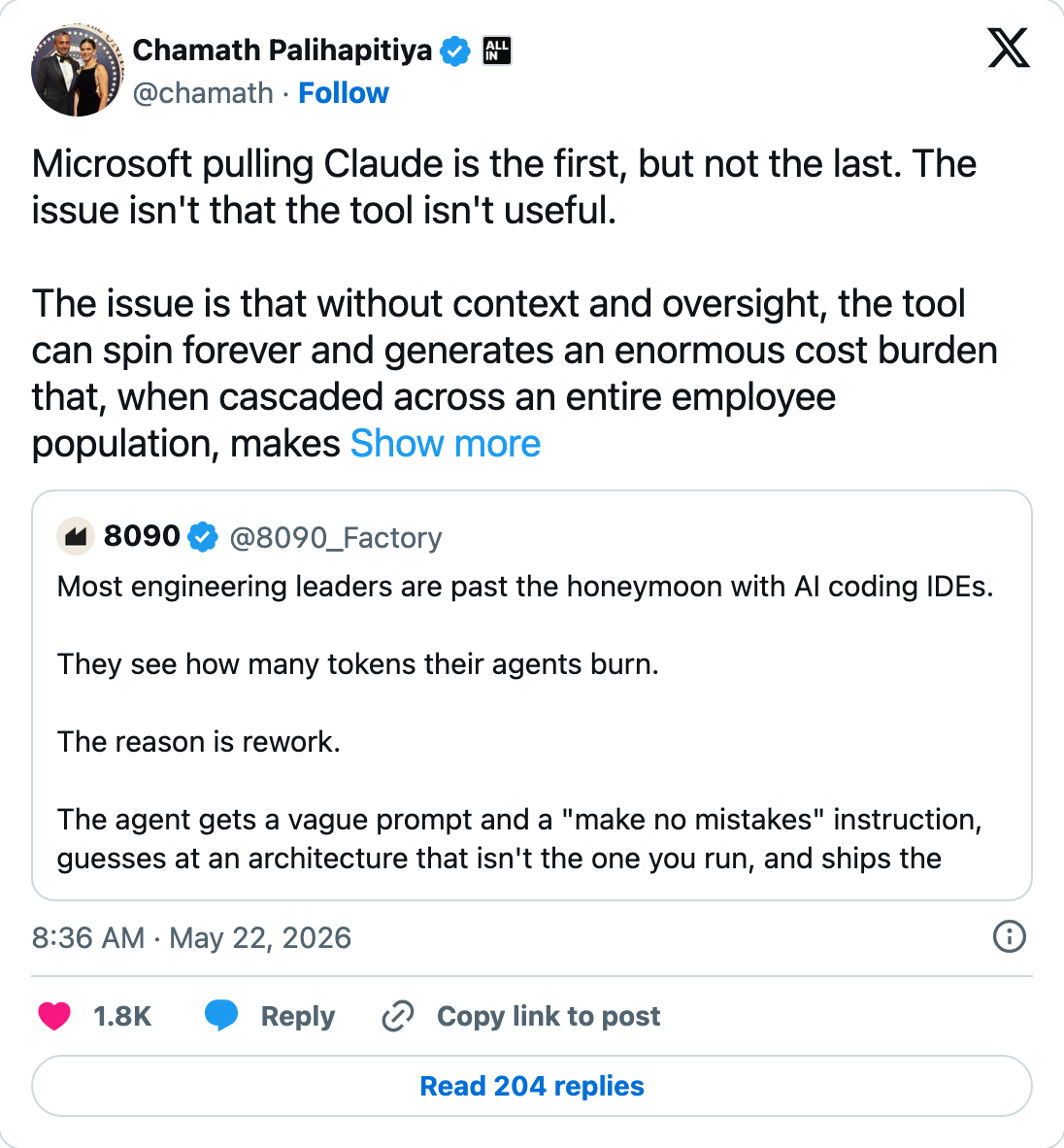
These are not five news items. They are five rotations of the same story: the agent layer is consolidating from a capability race into a platform race, and the platform substrate is observability. Lab cycles that used to ship the next benchmark-win are now shipping the next governance primitive. The shift is happening in real time — the same week chamath calls Microsoft “the first, but not the last,” Anthropic ships the exact dashboard that would have saved Microsoft’s deployment.
That timing is not coincidence. It’s product road-mapping under public-market pressure.
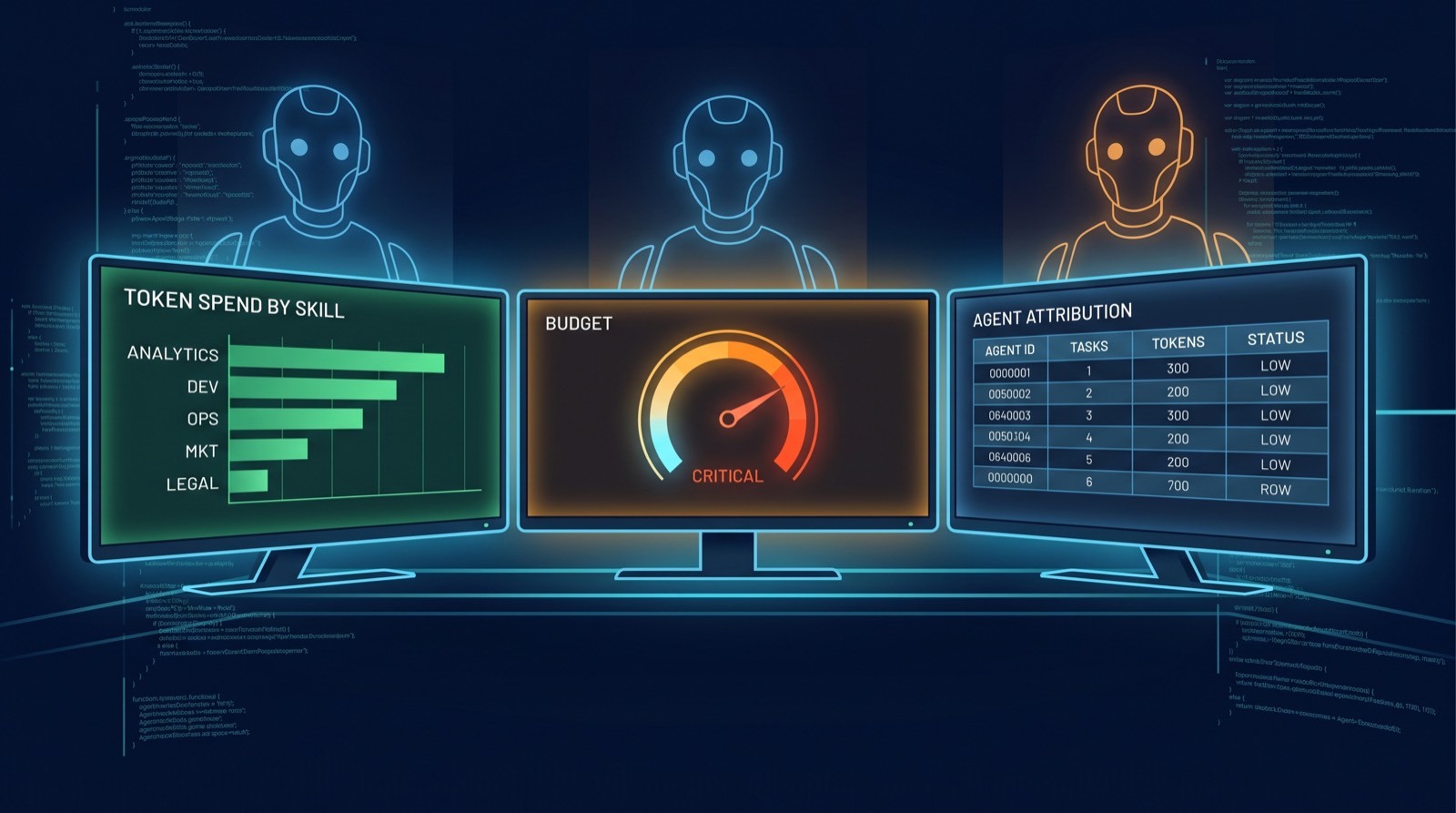
2. The agent observability stack — five primitives
If you’re a serious platform vendor in this space, here are the five primitives you have to ship. We’ve cross-referenced what each major player has — and where the gaps are.
Primitive 1 — Per-unit token attribution
Spend broken down to the callable unit the developer reasons about. For Claude Code that’s Skill / Agent / MCP / Plugin (/usage just shipped this). For Codex that’s the Goal / Plugin / Project. For Superset that’s the Workspace / Agent. For LangSmith that’s the Run / Chain.
| Vendor | Has it? | Granularity |
|---|---|---|
| Anthropic Claude Code | ✅ | Skill, Agent, MCP, Plugin |
| OpenAI Codex | ✅ | Goal, Plugin, Project |
| LangSmith | ✅ | Run, Chain, Node |
| Superset | ✅ | Workspace, Agent |
| Cursor | ⚠️ partial | Conversation only |
| Replit Agent | ❌ | Aggregate only |
The interesting reveal here is Cursor. The leading IDE-shaped coding agent still bills like a Q4 2024 product — by aggregate seat-month — while the agent vendors have already moved to per-unit. That is a strategic exposure when enterprise procurement gets serious about agent attribution.
Primitive 2 — Real-time budget caps with kill-switches
A hard cap, set by the developer or by an admin, that automatically halts execution when crossed. Not an alert — an interrupt. This is the primitive that would have prevented the Microsoft Claude Code blow-up: if the budget is $X for the deployment and the agent loop tries to exceed it, the agent is paused, not throttled. The Anthropic /usage ship is the read side of this; the write side (admin policy + enforced cap) is the next ship.
Primitive 3 — Per-agent provenance / decision trail
Every action the agent took — including the actions it chose not to take — needs to be queryable, attributable, and reproducible. This is where the agent judge layer pattern and the observability stack overlap. The judge tier writes its allow/deny decisions back into a provenance log; the observability tier reads that log and surfaces it to humans.
Primitive 4 — Per-MCP/tool spend attribution
If your agent uses an MCP server that charges per-call (database queries, paid APIs, image generation), the token bill is only half the story. The observability layer has to account for per-tool external costs alongside the LLM bill, or your dashboard is lying to your CFO. Anthropic’s /usage is the first major shipped version that includes MCP attribution by name. This is the primitive that turns “token spend” into “operational spend,” and operational spend is what procurement actually contracts on.
Primitive 5 — Cross-vendor unified dashboard
If you run Claude Code, Codex, and an in-house agent stack, you don’t want three separate dashboards. You want one pane. This is the LangSmith pitch, the OpenTelemetry-for-agents pitch, and (implicitly) the Superset pitch. The vendor that gets this layer cross-substrate-clean wins the “agent control plane” category — the one that gets to charge $10/seat/month on top of whatever the underlying models cost.
3. Why this is structurally Anthropic’s race to lose
Three independent signals point the same direction:
- The labor market is already pricing it. Karpathy joined Anthropic this week — and Polymarket’s “best AI model end of June” sits at Anthropic 74%, OpenAI 3%. When the market that prices conviction is at 74/24/3 and the marquee researcher just changed sides, the framing of the platform race has already started to consolidate.
- The compute side is already multi-cloud. Jensen named AWS, Azure, and CoreWeave as Anthropic compute providers at NVDA earnings. OpenAI is structurally Azure-exclusive. If the future product is “the agent observability layer,” the future-product needs deployment substrates that span procurement boundaries — and Anthropic just got that posture before OpenAI can match it.
- The product is already shipping. Anthropic ships
/usagein the same week as the Microsoft news cycle. That is not a roadmap claim; that is shipped product. Codex ships the developer-side update — Appshots, goals, plugins — which is excellent, but it’s an agent-features ship, not a governance ship.
Where this leaves the other vendors
- OpenAI: Strong agent-features cadence. Weak observability ship in this cycle. If the platform race is observability-first, OpenAI is structurally behind for at least one quarter. The fast catch-up move is Codex Admin — an enterprise-facing dashboard with per-Project / per-Plugin attribution. Don’t be surprised if that ships by July.
- Cursor: Most exposed. The aggregate-seat model is fine for individual developers; it does not survive enterprise procurement once an org has 50+ seats and a CFO. Either ships per-conversation attribution this quarter or starts losing the org rollout deals to Anthropic and Codex.
- Superset (just launched on HN): Plausible cross-vendor control-plane play. Will be acquired before the end of 2026 if execution is good — by Anthropic, by OpenAI, or by Datadog.
- LangSmith: Has the technical depth but not the distribution. Likely partner play, not standalone winner.
- GitHub Copilot + opencode + hermes-agent + the GitHub trending wave: Operating one layer below the platform race. Useful as primitives, not the platform itself.
4. What this means for operators
If you run Claude Code in production. Adopt /usage immediately and use it to write your first real per-team spending budget. Tie spending caps to specific Skills/Agents/MCPs — not aggregate. The aggregate dashboard is for the CFO; the per-unit dashboard is for the team lead who decides whether to merge that PR that introduces a new MCP.
If you run Codex in production. Your governance primitive is the Plugin / Project boundary. Establish budget alerts at the Project boundary before you scale headcount on it. Codex is shipping more features faster than it’s shipping more governance — that lopsided cadence will catch teams that don’t build their own observability layer on top.
If you run multi-model agent stacks. Stop pretending you can do this with the per-vendor dashboards alone. Pick a cross-vendor observability primitive now — LangSmith, Superset, or a self-hosted OpenTelemetry-for-agents — and standardize on it before the per-vendor dashboards diverge in ways that make migration painful. The first six months of any cross-vendor observability project is just data-plane work; you want to be done with that before procurement starts asking for spend attribution.
If you build agent infrastructure. The pure-capability play is closed. The remaining unbought layer is the control plane: per-unit attribution, cross-vendor unification, real-time policy enforcement. That is where the rest of 2026 will be decided. Read the related agent-judge-layer convergence — judge layers and observability layers will fuse into a single agent governance tier inside 12 months.
5. The 90-day forecast
By end of August 2026, expect:
- Anthropic ships budget caps — the write side of
/usage. Per-Skill / per-Agent / per-MCP enforced limits with admin policy. - OpenAI ships Codex Admin — Project-level governance dashboard. Likely paired with a Cisco-style enterprise reference customer (the May 22 Codex Cisco case study was a setup).
- Superset acquired or Series A’d at $1B+ — based on whether the cross-vendor control plane ships fast enough to matter.
- First Cursor enterprise loss to Claude Code attribution publicly written up. The decision will be cited as governance, not capability.
- OpenTelemetry-for-agents spec emerges — likely jointly authored by LangChain, Anthropic, and at least one observability vendor (Honeycomb or Datadog). This is the year governance becomes a formal standard, not just a vendor capability.
The companies that win the next 18 months of agent adoption will not be the ones with the fastest model on a cherry-picked benchmark. They will be the ones whose customers can prove, to a CFO, that the spend is bounded — line by line, agent by agent, MCP by MCP. The week of May 19–22, 2026, was the week the industry admitted that. Now the race is to ship the dashboard.
AgentConn covers the production agent stack — frameworks, governance, and the platform-tier patterns that separate demos from deployments. Related: The Agent Judge Layer: Validation Becomes Infrastructure and AI Agents Fail at Real Jobs: The Reliability Problem.