MDASH: How 100 Agents Beat One Frontier Model
Microsoft's MDASH scored 88.45% on CyberGym by orchestrating 100+ specialized agents. Here's the 5-stage pipeline and what it means for builders.

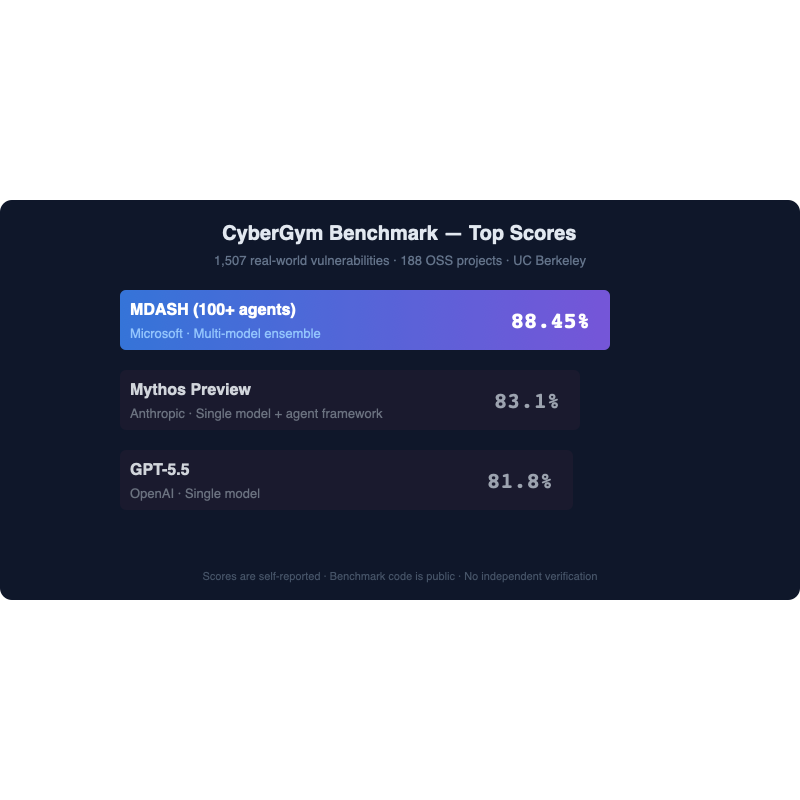
On May 12, Microsoft’s Autonomous Code Security team published a benchmark result that reframed the AI security conversation: their system, MDASH, scored 88.45% on the CyberGym vulnerability benchmark — five points ahead of Anthropic’s Mythos Preview (83.1%) and nearly seven ahead of OpenAI’s GPT-5.5 (81.8%).
The result was not surprising because MDASH used a better model. It was surprising because MDASH did not use one model at all. Microsoft stitched together publicly available models into a structured pipeline of more than 100 specialized agents — and that pipeline outperformed every single-model entry on the leaderboard.
For anyone building multi-agent systems, the implication is direct: when the task is complex enough, composition beats scale.
What MDASH Actually Is
MDASH stands for Multi-model Agentic Scanning Harness. Built by Microsoft’s Autonomous Code Security (ACS) team, it orchestrates 100+ specialized AI agents across an ensemble of frontier and distilled models to autonomously discover, debate, validate, and prove exploitable vulnerabilities in codebases.
The key design decision: MDASH is model-agnostic. Frontier models serve as heavy reasoners. Distilled models handle high-volume debate and filtering. A separate SOTA model acts as an independent counterpoint. Models can be swapped and A/B tested without rewriting pipeline stages — when a better model arrives, you change a config file, not your architecture.
💡 Key insight: As Microsoft’s VP of Agentic Security Taesoo Kim put it: “The harness does the work, and the model is one input.” If swapping a model requires rewriting your pipeline, you have built a model integration, not a system.
That framing is worth sitting with. In a world where the best model you depend on can vanish in 72 hours, the durable value sits in the orchestration layer — the system around the model — not in any single model itself.
Industry analyst Patrick Moorhead captured the significance of this shift:
The 5-Stage Pipeline
MDASH runs a five-stage pipeline where each stage is handled by a specialized cohort of agents. This is the architecture that beat Mythos:
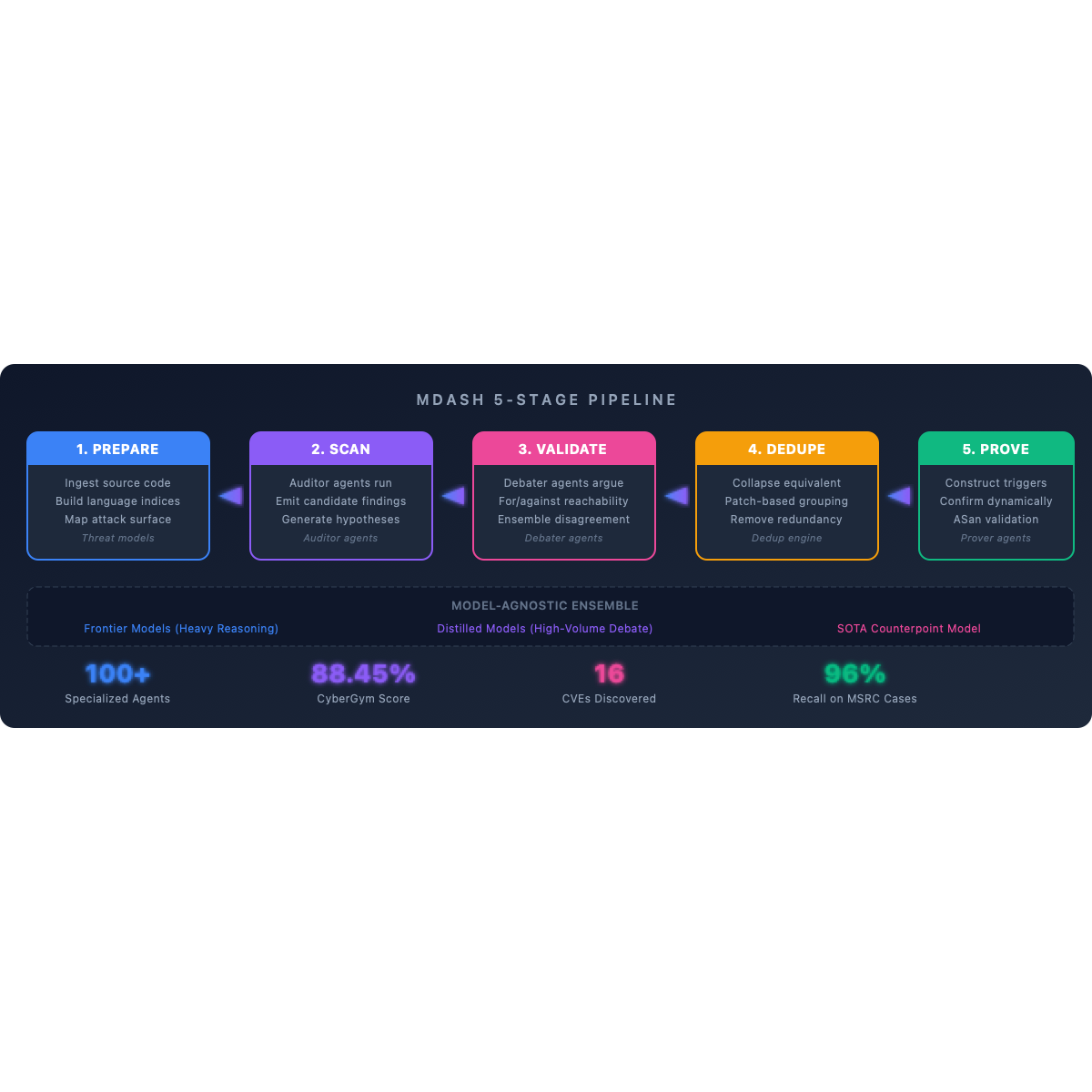
Stage 1: Prepare
The system ingests the source target, builds language-aware indices, and maps the attack surface by analyzing past commits. This stage draws threat models and identifies high-value code paths before any scanning begins.
Stage 2: Scan
Specialized auditor agents run over candidate code paths. Each auditor emits candidate findings with hypotheses and evidence. They generate theories about what could be wrong — but they do not validate those theories. That is someone else’s job.
Stage 3: Validate
A second cohort of agents — debaters — argue for and against each finding’s reachability and exploitability. This is where MDASH diverges most sharply from single-model approaches. When an auditor flags something as suspect and the debater cannot refute it, that finding’s posterior credibility goes up. The ensemble disagreement is the signal.
Stage 4: Dedupe
After validation, MDASH collapses semantically equivalent findings via patch-based grouping. Multiple auditors often flag the same underlying issue through different code paths — deduplication ensures the pipeline does not waste prover resources on redundant work.
Stage 5: Prove
Prover agents construct triggering inputs that confirm vulnerabilities exist dynamically. For C/C++ targets, they use AddressSanitizer (ASan) to confirm memory violations. This stage transforms theoretical findings into working proof-of-concept exploits.
The division of labor is the architectural insight. An auditor does not reason like a debater, which does not reason like a prover. Each pipeline stage has its own role, prompt regime, tools, and stop criteria. This specialization lets MDASH catch cross-file ownership bugs — where a memory-lifecycle violation only becomes visible by comparing patterns across several source files — that collapse into noise when a single model processes each function in isolation.
Why Composition Beat Scale
The CyberGym benchmark — developed by UC Berkeley researchers — measures how well AI systems can reproduce real-world vulnerabilities across 1,507 tasks drawn from 188 open-source software projects. Each task gives the system a vulnerability description and a codebase frozen at the pre-patch commit, and success requires producing a working proof-of-concept that triggers the flaw.
This is exactly the kind of task where single models hit a ceiling. The benchmark requires:
- Cross-file reasoning — finding bugs that span multiple source files and ownership boundaries
- Multi-step validation — confirming that a theoretical vulnerability is actually reachable and exploitable
- Proof construction — building a working exploit, not just flagging a suspicious pattern
No single model excels at all three. Mythos is a powerful model wrapped in an agent framework — but it is still one model doing everything. MDASH distributes the cognitive load across specialists, each optimized for their specific stage.
The composition thesis is simple: when the task decomposes into distinct subtasks that require different reasoning patterns, a pipeline of specialists outperforms a single generalist — even if the generalist is individually more capable on any one subtask.
Microsoft’s blog makes this explicit: “Discovery requires composition that no single prompt can achieve. The bugs found are not visible to a model handed a single function, but are visible to a system that can sequence cross-file pattern comparison, multi-step reachability analysis, debate between specialized agents, and end-to-end proof construction.”

The emphasis on end-to-end is key — the system does not hand off between stages; it owns the full loop.
The Benchmark Caveat
Let’s be honest about what we know and what we don’t.
⚠️ Benchmark caveat: CyberGym scores are self-reported. Microsoft, Anthropic, and OpenAI each ran their own systems against the benchmark and reported their own numbers. No independent third party has verified the submitted scores. Treat the exact percentages as directional, not definitive.
GeekWire’s Todd Bishop flagged this critical detail. The benchmark code is public, but the verification process is not. That does not make the results meaningless — but it does mean the precise margin should be held loosely. The architectural argument (composition > scale for complex multi-step tasks) is supported by the results, but not conclusively proven by them.
There is also the question of improvement trajectory. By Build 2026 on June 2, MDASH’s score had risen to 96.55% — a gain of approximately 10 percentage points in under three weeks. That jump likely reflects ongoing model-panel refinements (swapping in better models, tuning prompt regimes) rather than fundamental architecture changes. It also underscores the advantage of a model-agnostic system: the harness absorbs model improvements via config changes, not rewrites.
Real-World Results
The benchmark numbers matter less than what MDASH found in production. On its way to the May 2026 Patch Tuesday, MDASH discovered 16 previously unknown Windows vulnerabilities:
- 10 kernel-mode flaws including bugs in the TCP/IP stack and IKEv2 service
- 6 user-mode flaws across networking and authentication components
- 4 critical remote code execution vulnerabilities, including CVE-2026-33824 — a double-free in Windows’ IKEEXT service reachable remotely over UDP port 500 by an unauthenticated attacker
Microsoft is telling customers to expect bigger Patch Tuesdays going forward as AI-powered vulnerability discovery accelerates the rate at which flaws are found and fixed.
Historical validation was also strong: MDASH achieved 96% recall on 28 MSRC cases spanning five years for clfs.sys, and 100% recall on 7 cases for tcpip.sys. In a StorageDrive private test, it found 21 out of 21 planted vulnerabilities with zero false positives.
The real-world CVE output, not just the benchmark score, is what makes this system credible.
What This Means for Builders
MDASH is a cybersecurity system. But the architectural pattern — multi-model orchestration beating single-model scale — generalizes beyond security.
The core lesson: When your task has multiple distinct phases that require different reasoning strategies, build a pipeline of specialized agents rather than asking one model to do everything. This is the same insight behind Anthropic’s defending-code-reference-harness and the broader harness-as-moat thesis — the durable competitive advantage is in the system you build around models, not in which model you rent.
Practical patterns from MDASH that transfer to any multi-agent stack:
- Separate discovery from validation. Auditors and debaters have different objectives and different failure modes. Combining them in one prompt dilutes both.
- Use ensemble disagreement as signal. When multiple agents with different prompts and models disagree, that disagreement carries information. Build your pipeline to surface and use it, not suppress it.
- Make your system model-agnostic. If swapping a model requires rewriting your pipeline, you have built a model integration, not a system. MDASH absorbs model upgrades via config changes — so should yours.
- Deduplicate before expensive stages. Validation and proof-of-concept generation are the most compute-intensive stages. Removing redundant findings before they reach those stages is simple but high-leverage.
- Prove, don’t flag. The jump from “this looks suspicious” to “here is a working exploit” is the difference between a finding and actionable intelligence. Build your pipeline to go all the way.
For a deeper look at agent orchestration patterns and how different loop designs affect reliability, see our orchestration tools roundup. And for the other side of the coin — what happens when the frontier model your harness depends on gets banned — see the Mythos security agent review for context on the model MDASH just beat.
The question Microsoft is answering with MDASH is not “which model is best?” It is: “What can you build when you stop trying to find one model that does everything?”
The answer, apparently, is the top of the leaderboard.