Field report · · AgentConn Team
Loopcraft: Stop Prompting, Start Designing Loops
The shift from prompt engineering to loop engineering. How Karpathy, Steipete, and Boris Cherny design systems that prompt their agents.
On June 7, 2026, Peter Steinberger — the creator of OpenClaw — posted twelve words that ricocheted across every AI engineering corner of the internet: “You shouldn’t be prompting coding agents anymore. You should be designing loops that prompt your agents.”
The same week, Boris Cherny — creator and head of Claude Code at Anthropic — said the same thing on stage: “I don’t prompt Claude anymore. I have loops running. They’re the ones prompting Claude and figuring out what to do. My job is to write loops.”
Two builders. Same conclusion. Arrived at independently. And when Latent Space published “Loopcraft: The Art of Stacking Loops” the same week — weaving together Steinberger, Cherny, and Andrej Karpathy — it crystallized something that practitioners had been circling for months: the highest-leverage skill in AI engineering is no longer writing a good prompt. It’s designing the system that writes the prompts for you.
They’re calling it loopcraft. And it’s eating the harness layer.
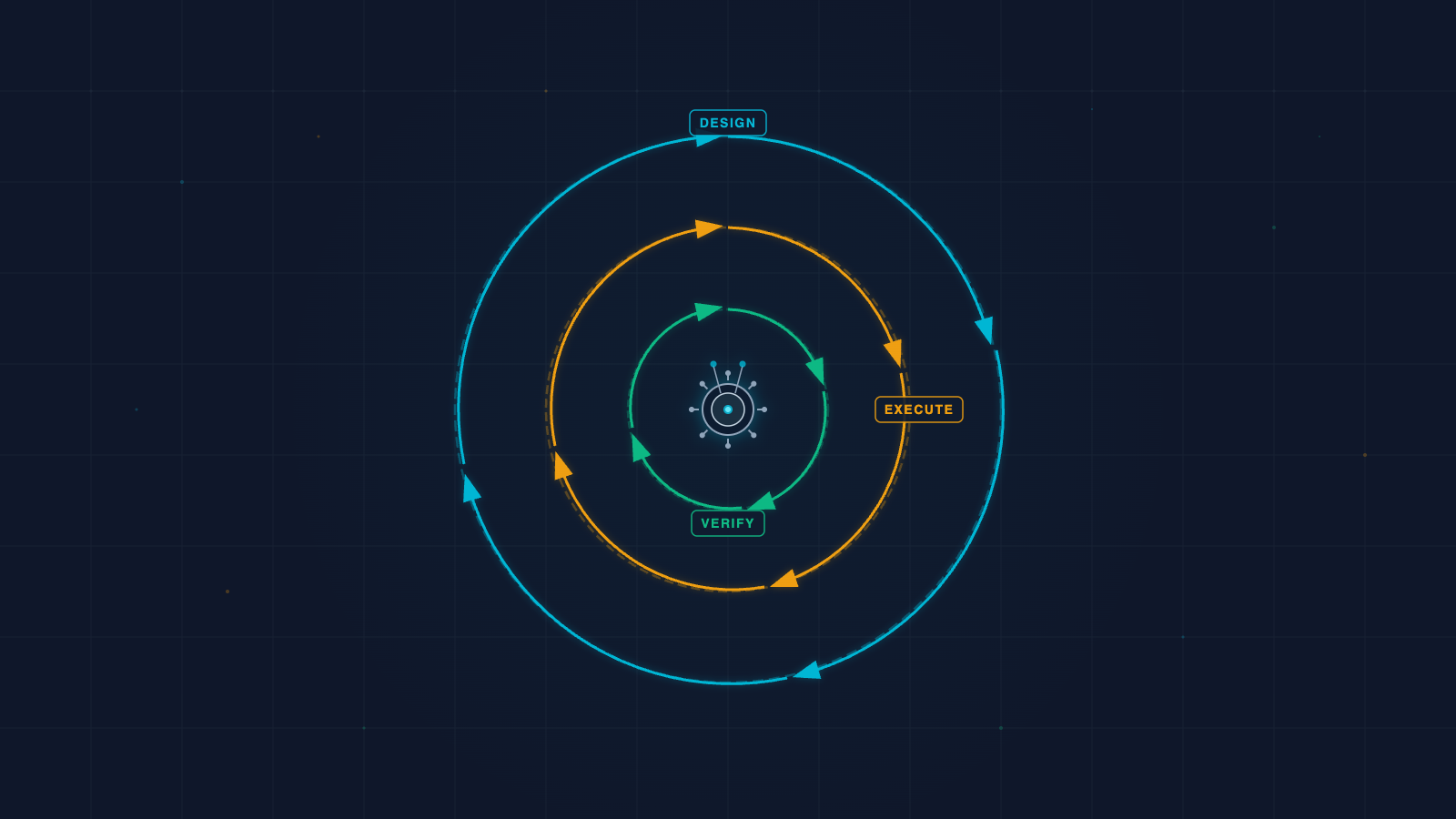
What a Loop Actually Is
Addy Osmani’s June 2026 essay — “Loop Engineering” — gave the concept its clearest definition. Loop engineering, he wrote, sits “one floor above” agent harness engineering. Instead of crafting one perfect instruction, you design the cycle that keeps an AI coding agent working, testing, learning, and stopping.

Osmani identified six primitives that compose a loop:
- Automations — scheduled triggers that start loops without human intervention
- Worktrees — isolated file-system branches so parallel loops don’t collide
- Skills — written-down project knowledge the agent can read and follow
- Connectors — tools the agent can call (APIs, databases, file systems)
- Sub-agents — maker/checker splits where one agent proposes and another verifies
- External state — memory and context that persists across loop iterations
This isn’t new territory conceptually. Simon Willison framed it in September 2025: “Designing agentic loops is a critical new skill to develop.” He defined agents as “things that run tools in a loop to achieve a goal” and argued that the art of using them well involves carefully designing the tools and the loop, not just the prompt.
The Hacker News thread on Willison’s essay drew hundreds of comments — practitioners sharing their own loop patterns, debating what “designing” even means in this context, and pushing back on whether this was just “scripting with extra steps.” (It isn’t. More on that below.)
What changed between Willison’s September 2025 framing and Steinberger’s June 2026 declaration is infrastructure. Back then, loops were theoretical. Now they’re shipping — and the tooling has caught up.
The Exemplar: autoresearch
If you want to understand what a well-designed loop looks like in practice, look at Karpathy’s autoresearch.
Released in March 2026, autoresearch is 630 lines of Python that ran 50 ML experiments overnight on a single GPU. The project picked up 21,000+ stars and 8.6 million views on Karpathy’s announcement within days.
Here’s why it matters: autoresearch doesn’t just automate a task. It automates the research loop itself — the cycle where a researcher forms a hypothesis, edits code, runs a training session, checks the result, and decides whether to keep the change. The agent reads a program.md file for research direction, modifies train.py with a proposed change, commits it, runs training for exactly 5 minutes, evaluates the result using val_bpb, and either keeps or reverts the change. Then it loops.
The most technically interesting thing about autoresearch is that the loop is defined in English. program.md is a document that specifies a complete research methodology: what to modify, what to leave alone, how to evaluate, how to handle failure cases, and a blanket prohibition on asking for help. A coding agent reads this document and executes it indefinitely.
This is the template for loopcraft: don’t give the agent a task. Give it a methodology. Let the methodology be the loop.
The ecosystem followed immediately. autoresearch-skill turned Karpathy’s pattern into a portable skill for Claude Code, Codex CLI, and Gemini CLI. Define a research.md, and the agent handles hypothesis generation, experimentation, evaluation, and iteration. Other variants emerged — interpretable-autoresearch added governance infrastructure, skills-autoresearch-flue added evaluation hooks.
The pattern is portable because the loop is the product. The research is just what fills it.
ℹ️ A loop is not a script. A script runs the same steps every time. A loop runs the same structure every time but lets the agent decide what fills each step. The agent isn’t following instructions — it’s following a methodology.
Loop Patterns That Ship
So what do production loops actually look like? Three patterns have emerged as the workhorses of the loopcraft era.
Find → Verify → Synthesize. The most common pattern. One agent (or fleet of agents) searches for something — bugs, information, files matching a pattern. A second fleet independently verifies each finding. A third synthesizes the verified results into a deliverable. Ken Huang’s deep dive on Claude Code orchestration documents this as the default pattern for code review workflows.
Loop-until-dry. For unknown-size discovery — audits, backlogs, edge cases — you keep spawning agents until K consecutive rounds return nothing new. Simple counters (while count < N) miss the tail. Loop-until-dry catches it because it doesn’t assume a fixed target.
Adversarial verify. Spawn N independent skeptics per finding, each prompted to refute. Kill the finding if a majority refute it. This prevents plausible-but-wrong findings from surviving the pipeline. The Neuron’s interview with Cherny and Cat Wu describes this as central to how the Claude Code team itself works — verification isn’t a step at the end, it’s a loop that runs in parallel with generation.
These patterns compose. A code audit might start with a multi-modal sweep (find by content, by file type, by commit history), pipe each finding through adversarial verify, and loop-until-dry until three consecutive rounds surface nothing new. The patterns are the reusable units, not the prompts.
💡 The counter-argument: “This is just scripting with extra steps.” The difference is that a script defines the steps. A loop defines the structure and lets an agent fill the steps. When the agent encounters something unexpected — a file in an unfamiliar format, a test failure with a novel error — a script fails. A loop adapts.
The Infrastructure Caught Up
What turned loopcraft from theory to practice is that the tooling shipped.
On May 28, 2026, Anthropic shipped ultracode — a Claude Code setting that activates automatic multi-agent workflow orchestration. Set effort to ultracode and Claude evaluates each request, deciding on its own whether the task warrants a full workflow. When it does, it writes a JavaScript script on the fly, plans an understand-change-verify loop, and dispatches subagents to work in parallel.
Dynamic Workflows replaced context-window orchestration with deterministic scripts. The script is the loop. It specifies what fans out, what verifies, what synthesizes. And because it’s a script — not a prompt — it’s reproducible, debuggable, and composable.

The Hacker News thread on LLM agent loops with tool use captured the shift: the community wasn’t debating whether loops work. They were debating which loop patterns work best for which tasks. The conversation had moved from “should we?” to “how?”
Meanwhile, the ecosystem materialized. obra/superpowers shipped a complete software development methodology built on composable skills — 1,276+ stars and growing. It works across Claude Code, Codex CLI, Gemini CLI, Cursor, and GitHub Copilot CLI. The skills are the building blocks; the loop is what stacks them.
The cobusgreyling/loop-engineering repo cataloged patterns from Osmani and Cherny into a practical reference. Suddenly there was a shared vocabulary: pipeline vs parallel, barrier vs streaming, phase-gated vs loop-until-dry.
⚠️ A caution on complexity: The most effective loops are often the simplest. Karpathy’s autoresearch is 630 lines. The temptation to build elaborate multi-agent orchestration for tasks that need a single well-prompted agent is real. Loopcraft isn’t about maximizing agents — it’s about maximizing leverage per loop iteration.
The Ecosystem Is Already Here
Pull up GitHub Trending for the past month and the pattern is unmistakable:
- agent-skills: +2,660 stars — auto-generated skills from trending AI repos
- superpowers: +1,276 stars — the full methodology framework
- autoresearch-skill: trending — Karpathy’s pattern as a portable skill
- cc-switch: +898 stars — harness switching between Claude Code, Codex, Gemini
The monoculture is skills, and the grammar for composing skills is loops. An autoresearch-skill defines a research loop. A deployment skill defines a CI/CD loop. A review skill defines a find-verify-synthesize loop. Stack them, and you have a complete production pipeline that runs while you sleep.
Boris Cherny confirmed the endpoint in March 2026: Claude Code is now 100% written by Claude Code itself. Across 259 pull requests in one month, Cherny didn’t open an IDE once. The loops handled everything — the generation, the testing, the review, the merge.
That’s not a productivity hack. That’s a new mode of engineering.
What Changes for Operators
If you’re building with AI agents today, here’s what loopcraft means for your workflow:
Stop optimizing prompts. Start optimizing loop structure. The marginal return on a better prompt is shrinking. The marginal return on a better loop — better verification, better composition, better stopping conditions — is expanding.
Write your methodology, not your instructions. Karpathy’s program.md is the template. Don’t tell the agent what to do. Tell it how to decide what to do, how to evaluate whether it worked, and when to stop.
Think in patterns, not tasks. Find-verify-synthesize. Loop-until-dry. Adversarial verify. These patterns compose across domains. Learn them once, apply everywhere.
The harness is commoditizing. The loop is the moat. Which harness you use (Claude Code, Codex, Gemini CLI) matters less every month. How you design the loop that runs on top of it — the skills, the verification, the orchestration — that’s where the leverage lives now.
Osmani said it most precisely: loop engineering sits one floor above harness engineering. The floor is open. The builders who move up first will have the most leverage.
The agents are waiting. Design the loop.
For a related look at how dynamic workflows are reshaping production deployments, see Claude Code Dynamic Workflows: From Salesforce Migration to Multi-Agent Orchestration. For the broader harness landscape, see Best AI Agent Orchestration Tools in 2026. And for the security implications of the skills supply chain, see Config Files That Run Code: The Agent Skill Supply Chain.