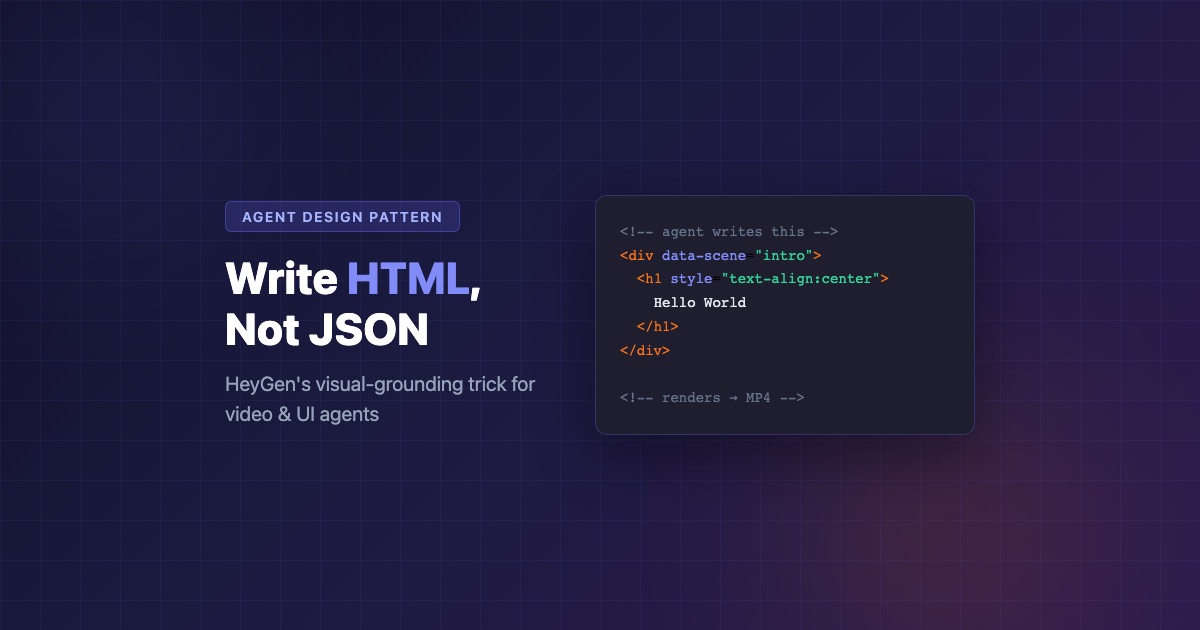
Write HTML, Not JSON: HeyGen's Visual-Grounding Trick
HyperFrames lets agents write HTML to produce video. The pattern works because LLMs can visually reason about HTML — and JSON can't carry layout.
Every agent framework in 2026 tells you to return structured JSON. Schema-validated, type-safe, parseable. And for most tasks, that’s correct — structured output gives agents 95–99% action success rates versus 70–85% for unstructured text.
But here’s the problem nobody talks about: JSON has no visual semantics. An agent can produce a perfectly valid JSON config describing a video timeline — correct schema, valid keyframes, legal property values — and the rendered output looks like garbage. The agent wrote “correct” instructions for something it can’t see.
HeyGen figured this out. Their open-source framework HyperFrames doesn’t use JSON configs. It uses HTML. And that single architectural choice — replacing a machine-readable format with a human-visual one — reveals a design pattern that matters far beyond video production: when the task has a visual dimension, give the agent a format it can see in its mind’s eye.
The Visual-Grounding Problem
When an agent generates a JSON video config, it’s working blind. Consider a simple scene:
{
"scenes": [{
"duration": 3,
"elements": [
{"type": "text", "content": "Hello", "x": 120, "y": 80, "fontSize": 24},
{"type": "image", "src": "logo.png", "x": 400, "y": 200, "width": 100}
],
"transition": "fade"
}]
}This is syntactically valid. The schema checker passes. But does “Hello” at position (120, 80) overlap with the logo at (400, 200)? Is the font size readable at that resolution? Does the fade transition make sense between these elements? The agent has no way to reason about any of this. It’s writing coordinates into a void.
The same problem hits every visual output domain. Diagram generators hallucinate overlapping nodes. Dashboard builders produce layouts that “work” in JSON but break visually. The SeeAct-V research confirms what practitioners already know: visual grounding — the ability to reason about what output looks like — is a fundamental capability gap for language models working in non-visual formats.
HyperFrames: HTML as the Agent’s Canvas
HyperFrames launched April 17, 2026, and hit 30,100 stars in two months. The pitch is three words: “Write HTML. Render video. Built for agents.”
Instead of JSON configs, agents write standard HTML with CSS and a thin layer of data-* attributes for timing:
<div data-scene="intro" data-duration="3s">
<h1 style="font-size: 48px; text-align: center; margin-top: 20vh;">
Hello World
</h1>
<img src="logo.png" alt="Logo"
style="position: absolute; bottom: 2rem; right: 2rem; width: 100px;"
data-enter="fade-in 0.5s" />
</div>The same information. But now the agent can reason about it. It knows what text-align: center looks like. It knows margin-top: 20vh pushes the heading down. It knows position: absolute; bottom: 2rem; right: 2rem puts the logo in the bottom-right corner. It knows these elements won’t overlap because it understands CSS layout.
The architecture is deliberately simple:
- CLI: scaffolding, preview, linting, rendering
- Core engine: headless Chrome orchestration for deterministic frame capture
- Producer: FFmpeg encoding to MP4
- Studio: browser-based editor for manual tweaks
- Lambda integration: distributed rendering at scale
Deterministic rendering means the same HTML produces the same video — every time. That’s not a nice-to-have for agent workflows. It’s the difference between “test this in CI” and “hope it looks right.” For production pipelines, determinism is table stakes: if you can’t reproduce a render, you can’t debug it, version it, or approve it in a review process. HyperFrames inherits this from the browser rendering model — Chrome’s layout engine is deterministic, so the video output is too.
The rendering stack uses Puppeteer to orchestrate headless Chrome and FFmpeg for encoding. This means any web technology that renders in a browser — including WebGL shaders and canvas-based visualizations — renders identically in HyperFrames. The technical ceiling is “anything a browser can display,” which in 2026 is effectively everything.
The framework supports GSAP 3, Lottie JSON, CSS transitions, Three.js, Anime.js, and WebGL shaders. Any animation library that runs in a browser works inside HyperFrames — no adapters needed.
Why HTML Wins Over JSON for Visual Output
The Hacker News discussion put it plainly: “It’s just a superset of HTML, and agents know how to write HTML + GSAP by default.”
This isn’t accidental. LLMs are trained on billions of web pages. They’ve seen more HTML than any other structured format. They know:
- What
display: flex; justify-content: space-betweenlooks like - That
border-radius: 50%makes a circle - That
font-size: 12pxis small andfont-size: 72pxis large - That
rgba(0,0,0,0.5)is a semi-transparent black overlay - That
gap: 1rembetween flex children creates breathing room
Compare this to JSON video configs. An agent writing {"fontSize": 24} has no intuition for whether 24 is appropriate. Writing font-size: 24px in a <style> block connects to real visual knowledge.
The HN thread highlighted another advantage over alternatives like Remotion: “Unlike Remotion, which requires custom adapters for each library, HyperFrames allows direct integration of any web library by default.” Remotion wraps everything in React. HyperFrames uses vanilla HTML. For an agent, there’s less framework-specific knowledge required — it’s just writing web pages.
There’s a quantitative angle too. Structured output research shows that schema-enforced JSON gives agents near-perfect format compliance — 95–99% valid output. But format compliance isn’t the same as output quality. An agent can produce 100% schema-valid JSON video configs where every single one renders poorly because the agent couldn’t reason about spatial layout in a non-visual format. HyperFrames trades format validation strictness for output quality by choosing a format the model can actually reason about visually.
The counterargument is real: HTML is token-heavy. A JSON config is compact; HTML with inline styles and semantic markup uses more tokens. For HyperFrames, this tradeoff is worth it because the output quality improvement outweighs the token cost. But it’s a tradeoff, not a free lunch. Teams running agents at high volume should benchmark whether the quality gain justifies the token spend for their specific use case.
The Agent Skill Architecture
HyperFrames doesn’t just accept HTML — it teaches agents how to write it. The framework includes dedicated skills for Claude Code, Cursor, Gemini CLI, and Codex that walk agents through the full video-production workflow: planning, HTML authoring, animation wiring, media integration, linting, preview, and rendering.
This is the skills-as-runtime pattern in action. The agent doesn’t need pre-existing knowledge of HyperFrames — the skill file teaches it the framework-specific conventions on demand. The heavy lifting — knowing how to write valid HTML, how CSS layout works, how to structure animations — comes from pre-training. The skill file just bridges the gap between “I know HTML” and “I know HyperFrames’ specific data-* attribute conventions.”
This is why the framework chose HTML over a custom DSL. A custom language would require the skill to teach everything from scratch. HTML lets the skill focus only on the delta: timing attributes, rendering commands, and project structure.
The results speak for themselves: HeyGen’s own launch video was made 100% with Claude Code + HyperFrames. No manual editing. No post-production. An agent wrote HTML, HyperFrames rendered video.
Nous Research’s Hermes agent has an official HyperFrames skill — the first major third-party agent framework to integrate video production as a native capability. Peter Yang’s walkthrough shows the full workflow from prompt to published video.
The security angle matters too. Every HyperFrames skill is a config file that runs code — the same supply-chain surface area we flagged in our skills audit. The Apache 2.0 license and 241 releases signal active maintenance, but teams should still vet skills before granting agent access.
What the Community Built
The adoption pattern tells you something. 30,100 GitHub stars in two months. Production use by HeyGen, tldraw, and TanStack. 241 releases. A reusable catalog of pre-built blocks for transitions, captions, charts, and effects that agents can compose without writing from scratch.
The Show HN thread was notably positive — rare for a Show HN. The main criticism was documentation, not architecture. Developers got the concept immediately because they already think in HTML.
One developer in the HN thread shared a similar HTML5/Canvas-based approach they’d built independently — the HyperFrames creator invited collaboration through pull requests. This isn’t one team’s idea catching on. It’s convergent evolution: multiple builders arriving at the same conclusion that HTML is the right output format for agent-generated visual content.
The convergence signal is strong. Our radar analysis flagged HyperFrames as a “tight named cross-source match” — YouTube, GitHub, and X all pointing at the same framework independently, not from coordinated marketing. That’s organic demand, not hype.
But HyperFrames is one implementation of a broader pattern. The question isn’t “should I use HyperFrames?” — it’s “am I giving my agents output formats they can reason about?”
The Visual-Grounding Pattern Beyond Video
The insight HyperFrames exploits is general: match the output format to the model’s strongest reasoning modality.
LLMs reason well about HTML because they’ve been trained on it extensively. They reason poorly about arbitrary coordinate systems, proprietary config schemas, and abstract layout descriptors — because they haven’t.
This pattern applies everywhere agents produce visual output:
| Domain | Low-Grounding Format | High-Grounding Format |
|---|---|---|
| Video | JSON timeline config | HTML + CSS + data-* attributes |
| Diagrams | DOT/Graphviz spec | SVG with semantic structure |
| Dashboards | Chart.js JSON config | HTML grid with inline chart components |
| Presentations | Slide JSON schema | HTML slides with CSS layout |
| MJML template variables | HTML email with inline styles |
The common thread: when the output format is something the LLM has deep training data for, the visual quality of agent-generated output improves dramatically. When it’s a proprietary format the model has to learn from a few examples in context, quality degrades.
This isn’t just about HTML. An agent generating SVG has visual grounding because it knows what <circle cx="50" cy="50" r="40"> looks like. An agent generating Graphviz DOT has less grounding because the relationship between rankdir=LR and the rendered layout is more abstract.
Who Should Use This
Use HyperFrames when:
- You’re building an agent that needs to produce video, animation, or visual content
- Your team already works in HTML/CSS and wants agents to share that skill set
- Deterministic rendering matters (CI/CD, automated pipelines, quality gates)
- You need to support multiple animation libraries without framework lock-in
Use Remotion when:
- Your team is React-native and the agent already works in JSX
- You need Remotion’s ecosystem of React-specific components
- You’re building a product where human editors and agents collaborate in the same React codebase
Build custom when:
- Your visual output domain is niche enough that no framework covers it
- The token cost of HTML output is a hard constraint (batch processing millions of items)
The open-source agent framework landscape now includes video production as a first-class capability. HyperFrames is the leading implementation, but the design pattern — giving agents a visually-grounded output format — is what matters most.
The broader takeaway extends beyond any single framework. The era of “give the agent a JSON schema and let it fill in the blanks” works for data exchange, API calls, and function parameters. But for any domain where the output has a visual dimension — layout, color, typography, animation, spatial relationships — the output format needs to carry visual semantics the model already understands.
HyperFrames is the first framework to make this bet explicitly and at scale. The creative AI agents space has been dominated by tools that treat agents as API callers — send a prompt to a rendering service and get output back. HyperFrames flips the model: the agent is the renderer. It writes the visual specification in a format it understands, and the framework handles the mechanical step of converting pixels to video frames.
HeyGen bet that agents think better in HTML than in JSON. Thirty thousand stars in two months suggests they were right. The question for every agent builder is: what format does your agent think in, and does that format let it see what it’s building?