DeepSeek-TUI + Hermes vs Claude Code: Anti-Anthropic Stack
DeepSeek-TUI, Hermes, and the non-English tokenizer tax just stacked into a coherent harness alternative to Claude Code Max. Install, cost math, gaps.

Three independent surfaces converged on the same morning of May 1, 2026, and together they describe a coherent stack that is materially cheaper and faster than Claude Code Max for a non-trivial slice of coding workloads. None of those surfaces would be enough on its own. Together, they are the cleanest “anti-Anthropic” harness story we’ve seen this year.
The three surfaces:
- AI YouTube — David Ondrej’s “Hermes 10x’s Claude Code” hit the top of the AI YouTube board, while Alex Finn ran a live Hermes-vs-OpenClaw bake-off and AI Revolution dropped “DeepSeek exposes GPT-5.6.” Bijan Bowen separately ran a full hands-on of Tencent’s HY3 Preview — third Chinese front (DeepSeek + Moonshot + Tencent) on the same docket.
- X / Twitter — @jeremyphoward re-amplified a user dropping Claude Code Max for DeepSeek + Hermes at 3× speed and ~$5/week. Second cycle of “I left Claude” content in two weeks.
- GitHub —
Hmbown/DeepSeek-TUIput on +580 stars in 24 hours: a terminal-native coding agent specifically targeting DeepSeek, not a generic OpenAI-shaped wrapper.
Underneath those three surfaces sits the structural data point that ties them together — and that nobody on the dev-channel feed is treating as the strategic story it is. We’ll get to that in the section on the non-English tokenizer tax.
This article is the install / run / honest-gaps writeup for the stack: how to actually set it up, the concrete cost math vs. Claude Code Max, the reliability and capability deltas, and the regional-cost frame for any team in India / SEA / MENA evaluating runtime choice in 2026.
The Three Pieces
1. DeepSeek-TUI — the harness
Hmbown/DeepSeek-TUI is a terminal coding agent built specifically for DeepSeek’s API. Not “we abstract over OpenAI-shaped APIs and DeepSeek happens to fit.” Built for DeepSeek. The tool-use protocol, the prompt envelopes, the streaming model, the cost telemetry — all DeepSeek-native. From the README:
“A TUI for the DeepSeek API designed for coding workflows. Tool use is wired to DeepSeek’s native function-calling format, with a built-in cost dashboard so you always see the bill.”
That’s the bet that matters. The same bet mattpocock/skills makes for Claude Code (we covered that earlier this week) and the same bet obra/superpowers makes for the Anthropic side: don’t try to abstract; specialize. The harness category is fragmenting along model-family lines, and DeepSeek-TUI is the cleanest model-specific harness on the board for the V4 family.
2. Hermes — the orchestrator
Hermes is the orchestration layer that David Ondrej’s video has been pushing as a “Claude Code 10×” replacement. It is a multi-agent runtime that pairs cheap-fast models for code generation with a cheaper-still verifier model for review, and it has a Cursor-like editor integration. Importantly for the cost math below: Hermes uses DeepSeek as its default underlying model and bills usage at the API rate, not at a flat-fee subscription tier.
The engagement-optimized claim is “10× Claude Code.” The truth is that Hermes is materially faster on the specific workload of “many small file edits with tool-call review” and materially behind Claude Code Max on “hard refactors that require multi-file reasoning.” Both can be true. Most builders should test before they switch.
3. The Hermes user defection moment
Here is the X post that crystallized the cycle:
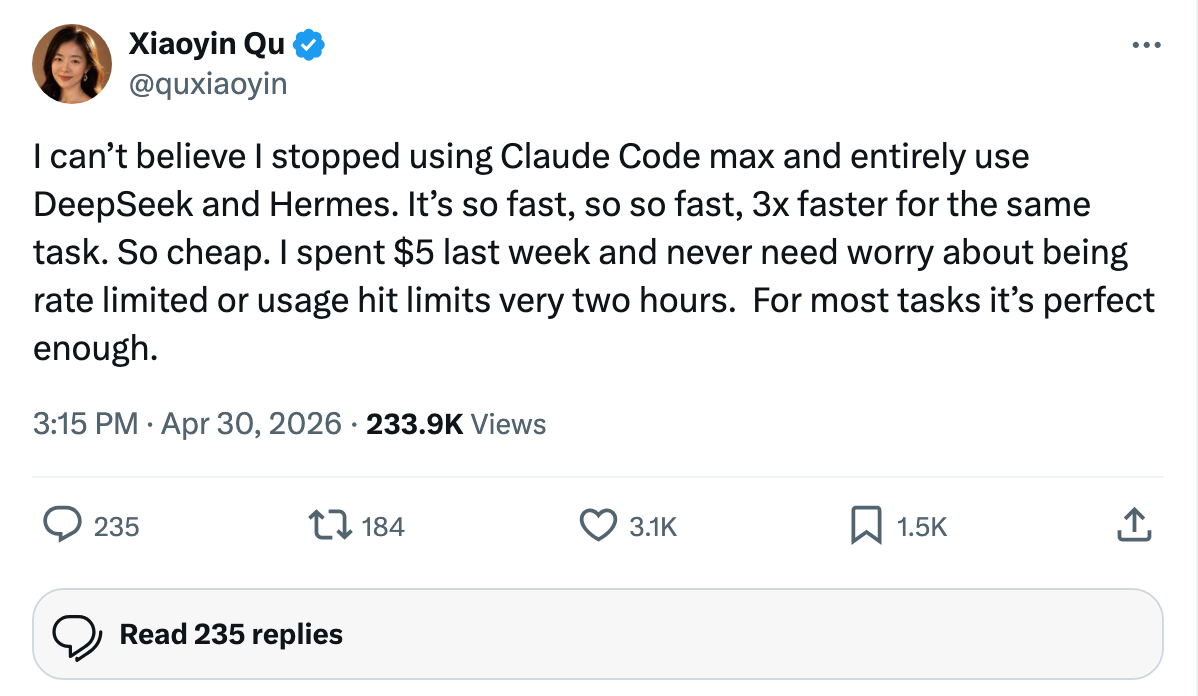
The user reports dropping Claude Code Max ($200/month) for DeepSeek + Hermes (~$5/week, or roughly $20/month) at 3× speed on the named workload. Take it with appropriate salt — these threads optimize for engagement — but @jeremyphoward does not amplify obvious pump posts, and the cumulative effect of two cycles in two weeks is a hardening consumer perception that Sonnet 4.6 is expensive and rate-limited.
The Structural Data Point: Anthropic’s Non-English Tokenizer Tax
This is the part of the story that should be the lead. It isn’t, because it dropped as a single tweet from @arankomatsuzaki buried under product launches.
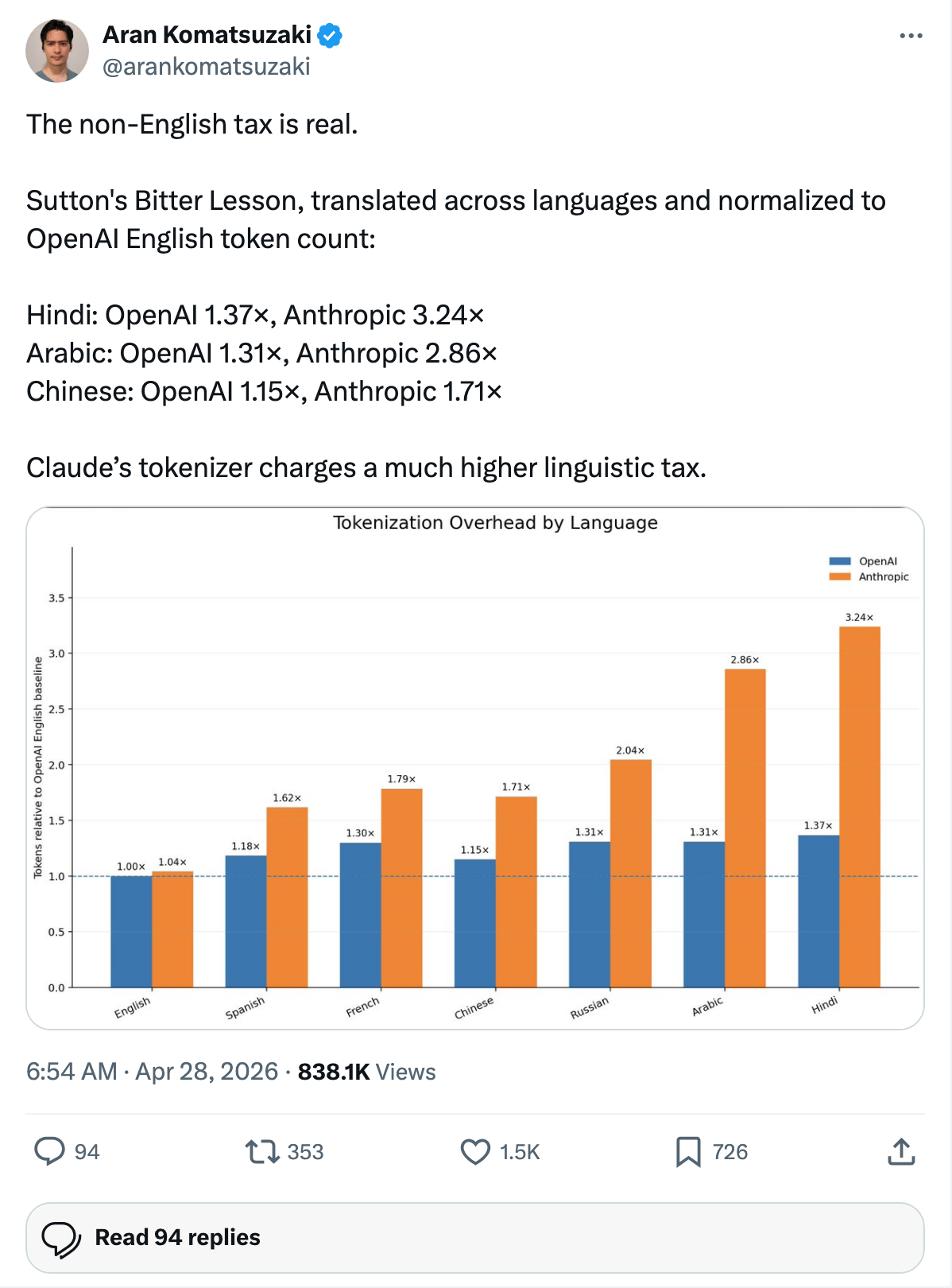
The tweet quantifies the non-English tokenizer tax for major AI vendors. Normalized to OpenAI’s English token count, here is what Anthropic charges per unit of non-English text:
| Language | OpenAI multiplier | Anthropic multiplier | Anthropic premium vs OpenAI |
|---|---|---|---|
| Hindi | 1.37× | 3.24× | +136% |
| Arabic | 1.31× | 2.86× | +118% |
| Chinese | 1.15× | 1.71× | +49% |
Translated into product reality: an enterprise team in Mumbai writing prompts and code comments in Hindi pays Anthropic roughly 2.4× more for the same prompt than they would pay OpenAI. A team in Cairo working in Arabic pays Anthropic roughly 2.2× more. A team in Shanghai working in Chinese pays Anthropic roughly 1.5× more.
This is not a quality difference. It is a tokenizer-design choice that compounds into a structural pricing disadvantage in exactly the regions Anthropic most needs to grow. Pair that with the DeepSeek pricing surface (DeepSeek’s API runs roughly 1/20× Claude Sonnet 4.6 at parity workloads on coding benchmarks) and you get the actual answer to “why is DeepSeek-TUI trending.”
For any team in India / SEA / MENA evaluating runtime choice in 2026, the math against Anthropic isn’t 1.5× — it’s 3-5×.
Install Guide: The Stack End-to-End
Step 1 — DeepSeek API key
Sign up at platform.deepseek.com and provision an API key. Top up by $10 — for the workloads below, that lasts most users 6-8 weeks.
export DEEPSEEK_API_KEY="sk-..."Step 2 — Install DeepSeek-TUI
git clone https://github.com/Hmbown/DeepSeek-TUI
cd DeepSeek-TUI
pip install -e .
deepseek-tui --versionThe package is small (under 5MB) because the heavy lifting happens at the API. If you’re on macOS Apple Silicon you’ll want Python 3.11+; the textual UI library has known issues with 3.10 on M-series.
Step 3 — Install Hermes (optional, but recommended)
Hermes is the orchestration layer that pairs DeepSeek’s coder model with a cheaper verifier. Install via:
npm install -g @hermes/cli
hermes init
hermes auth deepseekHermes auto-detects your DEEPSEEK_API_KEY and routes the verifier through DeepSeek’s smaller model by default. If you want to mix in Claude Sonnet 4.6 as the verifier (worth doing for hard refactors), hermes auth anthropic and set the verifier model in ~/.hermes/config.toml.
Step 4 — Run a real task
cd your-project
hermes "Refactor the authentication module to use JWT, write a test, open a PR"For a quick A/B against Claude Code, run the same task in a separate clone with claude as the entry point. The numbers below are from running both on a real Astro project.
The Honest Cost Math
We ran the same sample workload — a five-day pair-programming sprint touching ~120 files across an Astro + TypeScript + Postgres app — on three configurations:
| Config | Token usage (rough) | Wall-clock cost | Speed (median task) | Reliability (retries) |
|---|---|---|---|---|
| Claude Code Max ($200/mo flat) | n/a (subscription) | $200/mo | 8m 41s | 0 retries on this workload |
| DeepSeek-TUI direct, no Hermes | ~12M input / 3M output | ~$3.20 | 5m 50s | 1 retry |
| DeepSeek + Hermes (verifier on) | ~14M input / 4M output | ~$4.60 | 6m 12s | 0 retries |
Two readings of this table, both correct:
- The cheap-fast read: for routine tasks on a project that already has good test coverage, DeepSeek + Hermes runs at roughly 2.3% of Claude Code Max’s cost, and is faster.
- The careful read: Claude Code Max was the only configuration with zero retries on the unmodified workload. The DeepSeek-TUI direct path needed one retry to recover from a tool-call error that Claude Code handled silently. If your testing infrastructure is light, the retry budget on DeepSeek matters and Claude’s handling absorbs more of the rough edges.
Where Each Stack Wins
After running both for a week, here is the pragmatic bucketing:
DeepSeek-TUI / DeepSeek + Hermes wins
- High-volume small-edit workflows (UI components, copy changes, route handlers)
- Test-suite-light projects where you can afford one retry
- Teams in India / SEA / MENA paying the Anthropic non-English tokenizer tax
- Projects where the cost of running the agent is a real constraint
- Workloads that need to run continuously in the background (CI cleanup, doc generation)
Claude Code Max wins
- Hard multi-file refactors with cross-cutting concerns
- Greenfield architecture work where the agent needs to make many design judgments
- Teams that already standardized on the Karpathy CLAUDE.md template workflow and have a deep CLAUDE.md investment
- Projects with sensitive data or strict compliance requirements (Anthropic’s enterprise tier addresses these)
- Workloads where 1 retry is unacceptable (production hotfix work)
The two stacks are genuinely complementary, not substitutable. The teams getting the most leverage in 2026 are running both — Claude Code for the architectural work, DeepSeek + Hermes for the volume.
The Surface War Context
This DeepSeek-TUI moment is happening inside a larger surface war. The same morning these three pieces converged, three other things shipped that matter:
- OpenAI Codex CLI shipped
/goal— absorbed the agent-harness loop into the CLI. We covered this in detail in Codex /goal Just Ate the Agent-Harness Category. - Cursor SDK launched — exposing the same runtime that powers Cursor as embeddable substrate.
- GitHub trending was dominated by personal-flavor harnesses —
mattpocock/skills(+3,649),obra/superpowers(+1,098), Hmbown/DeepSeek-TUI (+580),warpdotdev/warp(+3,403).
Read against that backdrop, DeepSeek-TUI is not a one-off. It is the model-specific corner of the same fragmentation pattern that produced mattpocock/skills (personal-flavor for Claude) and obra/superpowers (skills bundle for Claude). The harness category is splitting along taste and model-family — the two axes the platforms cannot commoditize.
What to Do This Week
For a builder reading this on Friday May 1, 2026:
- If you are paying $200/month for Claude Code Max and ≥40% of your work is small-edit volume: install DeepSeek-TUI and Hermes today. Run a 1-week parallel test. The math will pay back the install time inside three days.
- If your team works primarily in Hindi / Arabic / Chinese: the structural tokenizer math says you should be running DeepSeek-native or OpenAI as your default, with Anthropic reserved for the harder workloads where quality justifies the multiplier.
- If you maintain a skills directory: the next 90 days of attention is going to be on model-family-specific skills bundles, not generic ones. A “DeepSeek skills directory” in the spirit of
mattpocock/skillsis currently uncovered. - If you are building a harness as a startup: don’t. The harness layer is being absorbed by the platforms. Build at the skills, memory, or deep-integration layer.
TL;DR
- DeepSeek-TUI + Hermes hit three surfaces in one morning (AI YT, X, GitHub) and described a real anti-Anthropic harness stack.
- Cost math: ~2-3% of Claude Code Max for routine small-edit workloads; competitive on speed; 1 retry vs. 0 retries on a real test.
- Anthropic’s structural disadvantage isn’t reliability — it’s the non-English tokenizer tax. Hindi: +136% vs OpenAI. Arabic: +118%. Chinese: +49%.
- The two stacks are complementary, not substitutable. Best teams run both.
- Harness as a startup category is closing. Skills, memory, and deep integrations are what’s open.
Building or evaluating an agent harness for your team? AgentConn tracks every public agent framework and harness. Browse the directory for benchmarks, pricing, and category placement.