The Agent Memory Wars Are Here
Graph memory beats flat RAG for coding agents. Supermemory, Mem0, Zep, and Headroom are the new infra tier.
The battleground for AI coding agents has moved. It used to be “which model.” Then it was “which harness.” Now it’s which memory layer — and the answer is splitting into three competing architectures that serve different use cases, at different costs, with different tradeoffs.
This week, five separate YouTube creators independently wrapped Claude Code in Skills + memory + evals “operating system” layers. GitHub Trending is dominated by agent memory infrastructure — Supermemory at 24.5k stars, Headroom climbing fast, and half a dozen graph-memory frameworks vying for the same slot in your agent stack.
The “Agentic OS gold rush” isn’t about models anymore. It’s about the infrastructure that makes models remember.
The Problem Flat RAG Doesn’t Solve
Traditional RAG — retrieve chunks by embedding similarity, stuff them into the prompt — was the 2024 answer to giving agents context. It works for simple lookups: “find the function that handles authentication” or “what did the error log say yesterday.”
But flat RAG loses relational structure between entities and events. When your coding agent needs to answer “why did we choose Postgres over MongoDB in the Q3 architecture review, and has anything changed since?” — that requires multi-hop reasoning across temporal relationships. Flat embeddings can’t do that.
The result: agents that forget what they learned two sessions ago, repeat the same mistakes, and lose the thread of multi-day refactoring work. Every developer who’s used a coding agent for more than a few hours has hit this wall.
The Three Architectures
The 2026 agent memory landscape has crystallized into three distinct approaches. Each solves a different slice of the problem.
1. Vector Memory (Flat RAG): Fast, Simple, Lossy
Frameworks like Mem0 sit between your LLM and a vector database, automatically extracting and storing facts from conversations. Mem0 gives agents a three-tier memory system — user, session, and agent scopes — backed by a hybrid store combining vectors, graph relationships, and key-value lookups.
Strengths: Fastest time-to-value. Drop-in integration with Claude Code, Cursor, and most MCP-compatible clients. Mem0 is the quickest path from zero to persistent agent memory.
Weakness: No temporal model. Memories are stored and retrieved, not modeled as time-bounded facts that can be superseded. If your agent needs to reason about how things changed — “the auth module was refactored last week, so that old pattern no longer applies” — Mem0 can’t reliably track that evolution.
2. Graph Memory (Structured RAG): Relational, Temporal, Complex
Graph memory transforms raw text into a structured knowledge graph. Cognee implements full GraphRAG — entities, relationships, and temporal edges that let agents trace reasoning paths across multiple documents and sessions.
Zep takes this further by storing every fact as a knowledge graph node with a validity window. “Kendra loves Adidas shoes (as of March 2026)” isn’t a string — it’s a fact with temporal bounds. On LongMemEval using GPT-4o, Zep scores 63.8% versus Mem0’s 49.0% — a 15-point gap driven by Zep’s temporal knowledge graph.
Strengths: Multi-hop reasoning. Temporal awareness. Entity-relationship queries that flat embeddings can’t touch.
Weakness: Setup complexity. Schema design. Graph databases aren’t a drop-in replacement for a vector store — they require upfront modeling of entity types and relationships.
3. Token Compression: Make the Context Window the Memory
The third approach doesn’t store memories externally at all. Instead, it compresses everything before it reaches the LLM.
Headroom is the leading example — an open-source context compression layer that intercepts LLM requests and applies intelligent compression. The published benchmarks: code shrinks 79.8%, JSON 59.2%, logs 31.0%, with a full multi-tool debugging session cutting 47.5% (~28,000 tokens).
Strengths: No external infrastructure. No schema design. Just smaller prompts. Especially powerful now that Claude Opus 4.7’s 1M flat-priced context window has made long-context a legitimate memory architecture for small agent fleets.
Weakness: Compression is lossy by nature. For agents with more than ~500K tokens of accumulated history or 100+ sessions, explicit memory becomes mandatory — you can’t compress your way out of a knowledge management problem.
Supermemory: The One to Watch
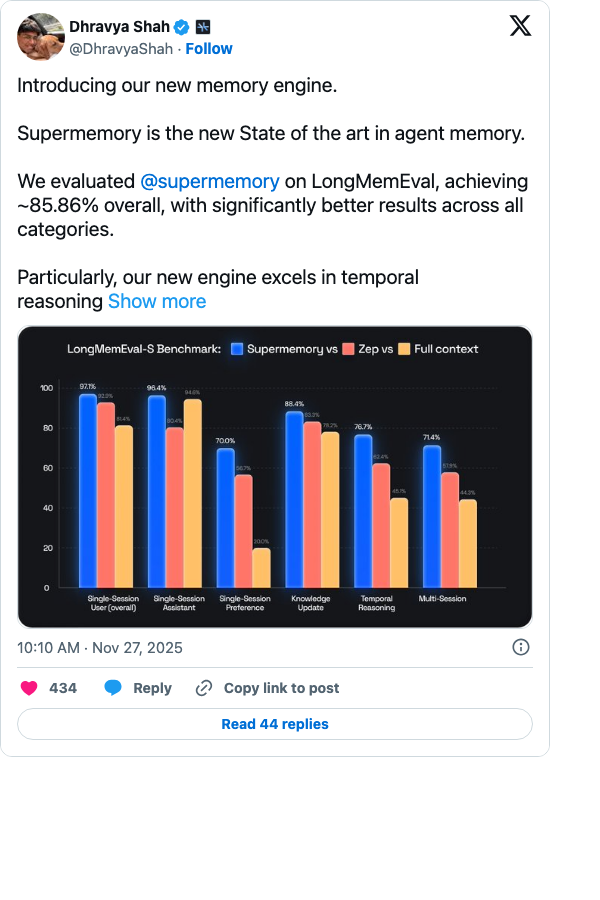
Supermemory (24.5k stars, $3M pre-seed) has emerged as the most complete implementation of the memory-as-infrastructure thesis. It ranks #1 on LongMemEval, LoCoMo, and ConvoMem — the three major benchmarks for AI memory.
What makes Supermemory interesting isn’t just the benchmarks — it’s the integration story. Claude Code now works with Supermemory, enabling stateful coding agents that learn across sessions. Hermes Agent added Supermemory as an officially supported plugin. OpenCode has its own Supermemory integration.
The architecture is a custom vector graph engine with context fencing — it automatically strips already-recalled memories from conversations, preventing the redundancy problem that plagues simpler memory systems.
The HN View: Memory Needs More Than RAG
The Hacker News community has been actively debating agent memory architecture throughout 2026. The consensus: flat similarity search is a solved problem, but structure over similarity is where the real gains are.
Competing approaches keep emerging — Hmem (hierarchical memory in SQLite), Engram (persistent memory as MCP server), YantrikDB (memory consolidation with contradiction detection) — each attacking a different weakness in the current toolchain.
The proliferation itself is the signal: the memory layer is unsettled infrastructure, and developers are still searching for the right abstraction.
The Operator Decision Framework
Here’s how to choose, based on where your agent sits in the complexity spectrum:
Use flat vector memory (Mem0) when:
- Your agent handles single-session tasks
- You need fast setup with minimal infrastructure
- Memory recall is simple — “what did the user prefer last time?”
- You have fewer than ~500K tokens of accumulated history
Use graph memory (Zep, Cognee) when:
- Your agent runs multi-day workflows across many sessions
- You need temporal reasoning — “what changed since the last deploy?”
- Entity relationships matter — “which services depend on this module?”
- You’re building enterprise-grade tools with compliance requirements
Use token compression (Headroom) when:
- You want to extend the effective context window without external infrastructure
- Your agent produces large tool outputs (logs, build output, test results)
- Cost optimization is a primary concern — 60-95% token reduction directly cuts API spend
- You’re already using a model with a large context window (1M+ tokens)
Use a hybrid (the 2026 pattern) when:
- You’re building production infrastructure that needs to handle all of the above
- You want graph memory for structured knowledge + compression for operational context
- For our earlier vectorless RAG decision guide, the same principle applies: match the retrieval architecture to the question type
The Hermes Integration Pattern
The convergence of Supermemory with Hermes Agent (179k stars) is the most significant integration pattern to watch. Hermes already provides the agent harness — skills, routing, tool orchestration. Supermemory adds the memory layer that makes it stateful.
This is the “Agentic OS” pattern in practice: the model is the engine, the harness is the chassis, and memory is the fuel system. Each layer is a separate infrastructure decision, and each has its own vendor landscape.
For a deeper look at how agent memory fits into the broader context-file pattern, see our earlier analysis.
The Cost Equation
Memory infrastructure adds a line item that didn’t exist six months ago. Mem0’s hosted tier runs about $50/month for moderate usage. Zep’s enterprise plan starts higher but includes the temporal knowledge graph that justifies the premium. Supermemory’s pricing tiers scale with memory operations — and at 24.5k stars, the open-source self-hosted option remains viable for teams that want to own the infrastructure.
The token compression approach has the simplest cost story: Headroom saves you money directly. If your agent spends $100/month on API calls and Headroom compresses 50% of those tokens, the savings are immediate and measurable. No new infrastructure, no new vendor — just smaller bills.
The real cost comparison, though, isn’t framework-to-framework. It’s the cost of memory infrastructure versus the cost of an agent that forgets. When a coding agent repeats the same wrong approach three sessions in a row because it has no persistent memory, the developer time wasted dwarfs any framework subscription.
What’s Next
The memory wars are just starting. Three things to watch:
-
Benchmark convergence. LongMemEval, LoCoMo, and ConvoMem are the current standards, but they test different things. A unified benchmark that covers temporal reasoning, multi-hop retrieval, and compression fidelity would clarify which architectures actually win in production.
-
MCP standardization. Memory is becoming an MCP server pattern — Mem0, Supermemory, Hmem, and Engram all expose memory through MCP. As the protocol matures, expect plug-and-play memory swapping across agent harnesses.
-
The compression-memory hybrid. Headroom + Supermemory is the stack nobody’s built yet. Compress the operational context, persist the structured knowledge. The agent that combines both will have the best cost-performance ratio in the market.
The model race gave us capability. The harness race gave us orchestration. The memory race will give us continuity — and continuity is what separates a tool from a colleague.