HuggingFace ml-intern: Open-Source ML Research Agent
ml-intern is HuggingFace's open-source AI agent that reads papers, discovers datasets, and trains models autonomously — outperforming Claude Code on GPQA.
HuggingFace ml-intern: The Open-Source Agent That Reads Papers and Trains Models
On April 21, 2026, HuggingFace shipped ml-intern — an open-source AI agent that automates the end-to-end ML post-training loop. Within days, it hit GitHub’s #1 trending spot with 6.3k stars. The headline result: ml-intern pushed a Qwen3-1.7B base model from a 10% baseline to 32% on GPQA in under 10 hours on a single H100 — beating Claude Code’s 22.99% on the same benchmark.
For ML practitioners, the question isn’t whether it’s impressive. The question is whether it’s actually useful in your workflow. This is a hands-on guide: what ml-intern does, how to set it up, and when it’s the right tool versus when you should stick with what you have.
What Problem ml-intern Is Solving
The post-training workflow for an LLM isn’t one step — it’s a research loop that typically takes a human engineer 2–5 days per iteration:
- Read recent papers on arXiv and HuggingFace Papers to identify relevant techniques
- Walk citation graphs to find the datasets those techniques use
- Pull those datasets from HuggingFace Hub, inspect for quality, reformat for training
- Write a training script (GRPO, SFT, DPO, or whatever the paper calls for)
- Launch the job on a GPU cluster, monitor metrics
- Read eval outputs, diagnose failures (reward collapse, overfitting, distribution shift)
- Retrain with adjustments, repeat
ml-intern encodes this loop as an agent. It runs up to 300 iterations, with each iteration calling tools across arXiv, the HuggingFace Hub, GitHub code search, and HuggingFace Jobs. The output isn’t a suggestion — it’s a trained model checkpoint.
What makes this different from a coding assistant: Claude Code or Copilot can help you write the training script. ml-intern runs the script, reads the eval output, decides what to change, and reruns — without prompting you between iterations.
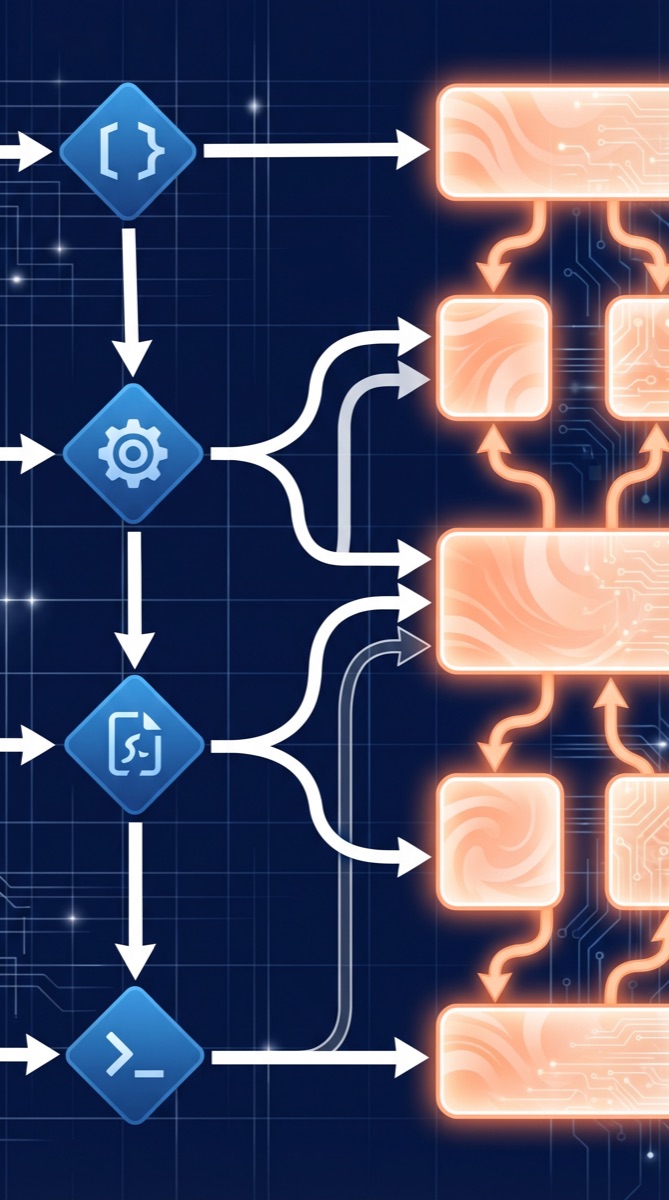
Architecture: How It Actually Works
ml-intern is built on HuggingFace’s smolagents framework, which treats tool calls as Python code rather than JSON function-calling payloads. This matters for ML workflows: calling dataset.filter(lambda x: x['quality'] > 0.8) is more natural than JSON-encoding the same operation.
The three architectural components worth understanding:
ContextManager (170k token auto-compaction): ML research contexts get long — a 300-iteration run accumulates papers, code diffs, eval logs, and training metrics. The context manager handles history and auto-compacts at 170k tokens, preventing the agent from running out of context on long training runs.
ToolRouter: Routes calls to HuggingFace docs, arXiv, HuggingFace Papers, dataset search, GitHub code search, HuggingFace Jobs, and sandboxed execution. MCP server support means you can extend it with custom tool servers — internal dataset registries, private model hubs, or company-specific training infrastructure.
Doom-loop detector: This is the practical innovation. Agentic loops fail by getting stuck: the agent tries the same failing approach repeatedly, burning your GPU budget. The doom-loop detector identifies repeated unproductive patterns and forces a direction change. In the launch demo, it caught a reward collapse pattern that would have run for 40+ iterations before hitting the iteration cap.
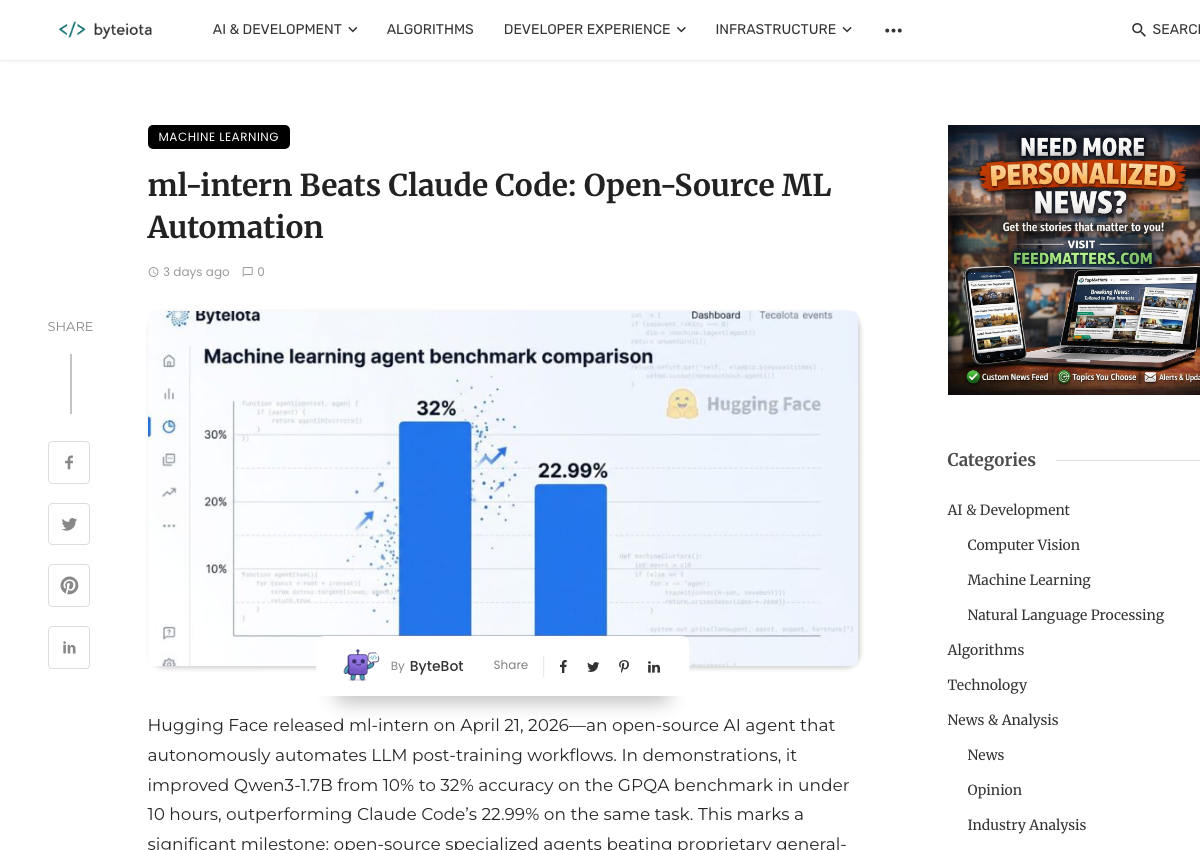
Benchmark Results: PostTrainBench
The benchmark ml-intern was evaluated on is PostTrainBench — a 10-hour challenge from researchers at the University of Tübingen and the Max Planck Institute. The setup: given a base model and a single H100 GPU, post-train the model to improve performance across 7 benchmarks covering reasoning, math, tool use, knowledge, code, and health.
| Agent | GPQA Score | Method |
|---|---|---|
| Qwen3-1.7B baseline | ~10% | No training |
| Claude Code | 22.99% | SFT runs |
| ml-intern | 32% | 12 SFT passes, iterative refinement |
The 32% result came from 12 supervised fine-tuning passes on Qwen3-1.7B. The agent crossed 27.5% in just over 3 hours, then continued iterating. The final result is 9 percentage points above Claude Code’s result.
Additional demo results:
- HealthBench: ml-intern generated 1,100 synthetic data points (emergency, multilingual, client communication) and beat Codex by 60%
- Math (GRPO): The agent implemented Group Relative Policy Optimization autonomously, launching on A100 GPUs via HuggingFace Spaces
Setup Guide
Requirements:
- Python 3.10+
uvpackage manager (install:curl -LsSf https://astral.sh/uv/install.sh | sh)- API keys:
ANTHROPIC_API_KEY,HF_TOKEN,GITHUB_TOKEN
Installation:
git clone https://github.com/huggingface/ml-intern
cd ml-intern
uv sync
uv tool install -e .Run interactively:
ml-internSingle-shot command:
ml-intern "Fine-tune Qwen3-1.7B on medical QA using synthetic GRPO data"If you don’t have a local GPU, the agent will automatically route training jobs to HuggingFace Jobs. HuggingFace is also providing $1,000 in GPU credits and Anthropic credits for early users — apply through the HuggingFace Space at huggingface.co/spaces/smolagents/ml-intern.
MCP server configuration (optional):
To extend ml-intern with custom tools, add an mcp_config.json with server transport type, URL, and authorization headers. This is how teams with internal dataset registries or private compute clusters can wire ml-intern into their existing infrastructure.
When to Use ml-intern vs Alternatives
ml-intern isn’t a replacement for general-purpose coding agents. It’s a specialized tool for a specific workload.
Use ml-intern when:
- You’re running LLM post-training experiments (SFT, GRPO, DPO, RLHF)
- You want to automate the paper-to-dataset-to-training loop
- You’re using HuggingFace infrastructure (Hub, Jobs, Papers)
- You need iterative refinement across multiple training runs
Stick with Claude Code when:
- You’re doing general software engineering (Claude Code scores 80.8% on SWE-bench — ml-intern isn’t competitive here)
- You need interactive, exploratory collaboration rather than autonomous execution
- The task isn’t ML post-training specific
Consider Devin when:
- The task is well-defined with clear success criteria and you want async execution
- You need human-in-the-loop approval gates on destructive operations
The key insight from Adithya Giridharan’s Medium analysis: ml-intern bets on ecosystem access as its moat, not raw model capability. The value isn’t the agent’s reasoning — it’s the tight integration with arXiv, HuggingFace Hub, HuggingFace Jobs, and Trackio. A general-purpose agent with the same underlying model won’t automatically have those integrations wired correctly.
Community Reaction
The launch framing resonated with ML practitioners. Aksel Joonas Reedi (HuggingFace AI agents team) described it as an agent that “deeply embodies how researchers work and think” — knowing how data should look and what good models feel like.
The Todatabeyond Substack analysis captured the architectural distinction: ml-intern’s design “reads like an attempt to take the actual shape of ML research and encode it into an agent” — a workflow system rather than a chat interface with tools bolted on.
The benchmark comparison to Claude Code generated the most discussion. Byteiota’s analysis noted the important caveat: Claude Code scores 80.8% on SWE-bench, which ml-intern doesn’t approach. The GPQA result isn’t a general intelligence comparison — it’s a domain-specific result on a domain where ml-intern was purpose-built to excel.
The 6.3k stars in four days is real signal. The Product Hunt listing was also well received, with HuggingFace offering the $1,000 in combined GPU and API credits making it easy to try on real tasks without an initial cost barrier.
Limitations Worth Knowing
Local GPU required for best results. HuggingFace Jobs integration works for cloud routing, but the iteration loop is faster when you have a local H100. The 10-hour benchmark window becomes a real constraint if you’re routing through remote jobs with queuing delays.
HuggingFace ecosystem lock-in. The dataset discovery and training job routing are built specifically for HuggingFace infrastructure. Teams using internal dataset storage, AWS SageMaker, or GCP Vertex AI for training will need custom MCP adapters to get the same level of integration.
300 iterations is a hard cap. The bounded iteration design prevents runaway compute spend, but it also means complex tasks that need more exploration may hit the cap before converging. The doom-loop detector helps, but it can’t fully substitute for human judgment on whether to continue a training direction.
Context compaction trade-offs. The 170k token auto-compaction keeps long runs working, but it loses detail from early iterations. If the agent’s failure diagnosis in iteration 250 would benefit from remembering exactly what happened in iteration 50, the compacted context may not have that detail.
Verdict
ml-intern is a real tool for a real workload. If you run LLM post-training experiments on a regular basis, the automation of the paper-to-dataset-to-training loop is genuinely valuable — the 300-iteration bounded execution, doom-loop detection, and HuggingFace ecosystem integration are well-designed for the task.
The benchmark headline (beats Claude Code on GPQA) is accurate in context but easy to misread. Claude Code is a general-purpose engineering agent; ml-intern is a post-training specialist. They’re not competitors — they’re tools for different jobs.
The $1,000 in early-access credits makes it worth trying on a real task before deciding whether it fits your workflow. The CLI is straightforward to set up, and the HuggingFace Space means you can test it without any local environment configuration.
See the full ml-intern directory entry for a quick-reference spec sheet of capabilities, pricing, and alternatives.
Sources: GitHub · HuggingFace Blog · PostTrainBench · MarkTechPost · EdTech Innovation Hub · Substack · Medium