Field report · · AgentConn Team
The Harness Is the Moat
The Fable 5 ban proved the model is not the moat. Operators who built orchestration loops barely flinched — here is why harness investment is ban-proof.

On June 12, 2026, the US Commerce Department ordered Anthropic to suspend all access to Fable 5 and Mythos 5 — the most capable AI models ever released to the public — for any foreign national. Within hours, both models went dark for everyone. Three days from launch to kill switch.
The AI industry panicked. Enterprise contracts were voided overnight. Prediction markets repriced. Hacker News hit 2,944 points on the thread. But a specific cohort of builders barely flinched: the teams that had invested in agent orchestration harnesses.
Their workflows kept running. Their agents kept shipping code. The model underneath changed — they swapped to Opus 4.6 or GPT-5.5 or Gemini 3 — and the orchestration layer didn’t care. That’s the thesis: the harness is the moat, not the model.
What Happened — and Who It Didn’t Happen To
The Fable 5 ban was triggered by Amazon demonstrating the model’s cybersecurity capabilities to government officials. A cybersecurity CEO who reviewed the actual research called it “a defensive probing technique, not an offensive jailbreak”. But the framing mattered more than the technical reality, and Commerce Secretary Lutnick sent the letter.
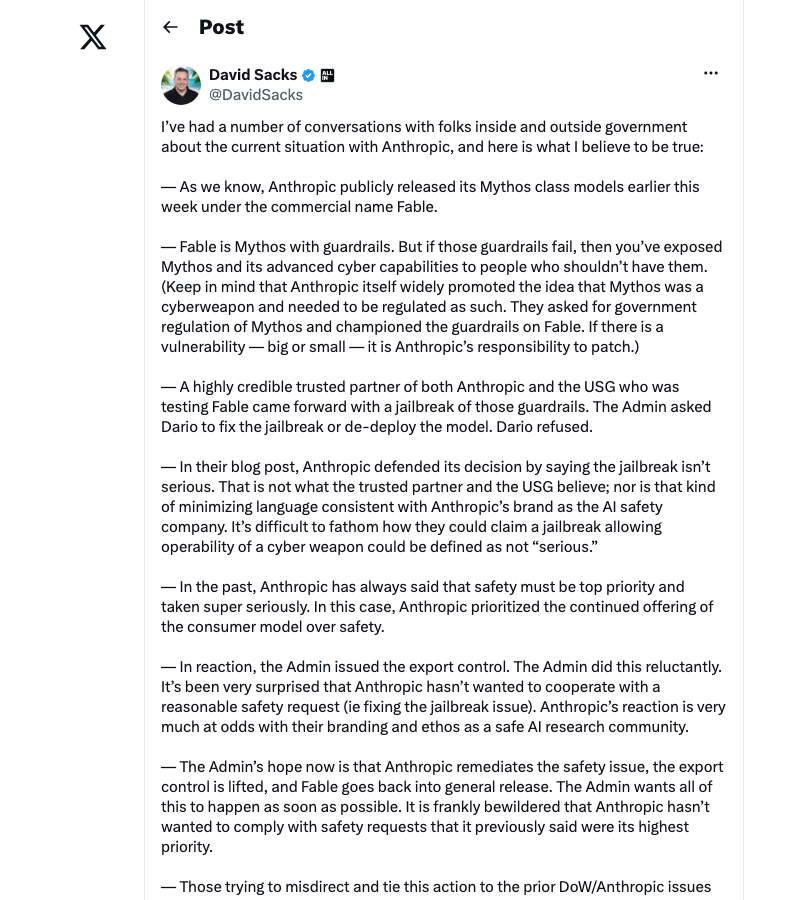
David Sacks, the White House AI advisor, publicly signaled backchannel government conversations about the ban. The political machinery moved faster than any technical review process.
But here’s the split that matters for builders: teams that had hardcoded claude-fable-5 into their pipelines were dead in the water. Teams that had built model-agnostic orchestration harnesses — with fallback routing, multi-provider support, and business logic separated from the inference layer — swapped models in minutes.
Anthropic’s own statement acknowledged the asymmetry: the export control was a de facto global ban because “unable to verify citizenship in real time, Anthropic made the call to pull both models offline entirely.” If your architecture assumes a specific model will always be available, you’re building on sand.
The SWE-bench Signal Nobody Talks About
The harness-vs-model debate isn’t new, but a specific datapoint from SWE-bench crystallizes it. As FourWeekMBA documented: swapping the harness changes SWE-bench scores by 22 points. Swapping the model changes scores by only 1 point.
Read that again. The orchestration layer — the loops, the tool routing, the retry logic, the context management — contributes 22x more to benchmark performance than the model itself. This isn’t a marginal difference. It’s a structural one.
This is why the Fable 5 ban was a stress test, not a catastrophe, for harness-first teams. When Aakash Gupta wrote “2025 was agents, 2026 is agent harnesses”, he was describing the exact dynamic that the ban exposed. The model is becoming a commodity input. The harness is where the value accrues.
Visrow’s analysis of harness engineering goes further: “Business logic lives in the harness — the model layer is commodity.” When your harness encodes your team’s domain knowledge, workflow patterns, and quality gates, a model swap is a config change, not a rewrite.
GitHub Trending Proves the Thesis
If you want to know where engineering investment is flowing, look at GitHub trending the week the ban dropped. The signal is unmistakable:
agent-skills — Addy Osmani’s collection of reusable agent capabilities — gained +1,507 stars in a single day. This isn’t a model. It’s a library of harness components: structured skill definitions that any model can execute.
superpowers — the agentic skills framework that now sits at 224,691 total stars — added +931 stars. Superpowers doesn’t care which model runs underneath. It defines the orchestration patterns, the skill interfaces, and the execution loops. AIToolly’s review called it “a structured way to build and manage AI agent capabilities” — and that structure is exactly what survives a model ban.
NVIDIA SkillSpector — a security scanner for agent skills — gained +809 stars. This is the counter-signal that confirms the thesis has matured: when a technology gets its own security tooling, it’s no longer experimental. It’s infrastructure.
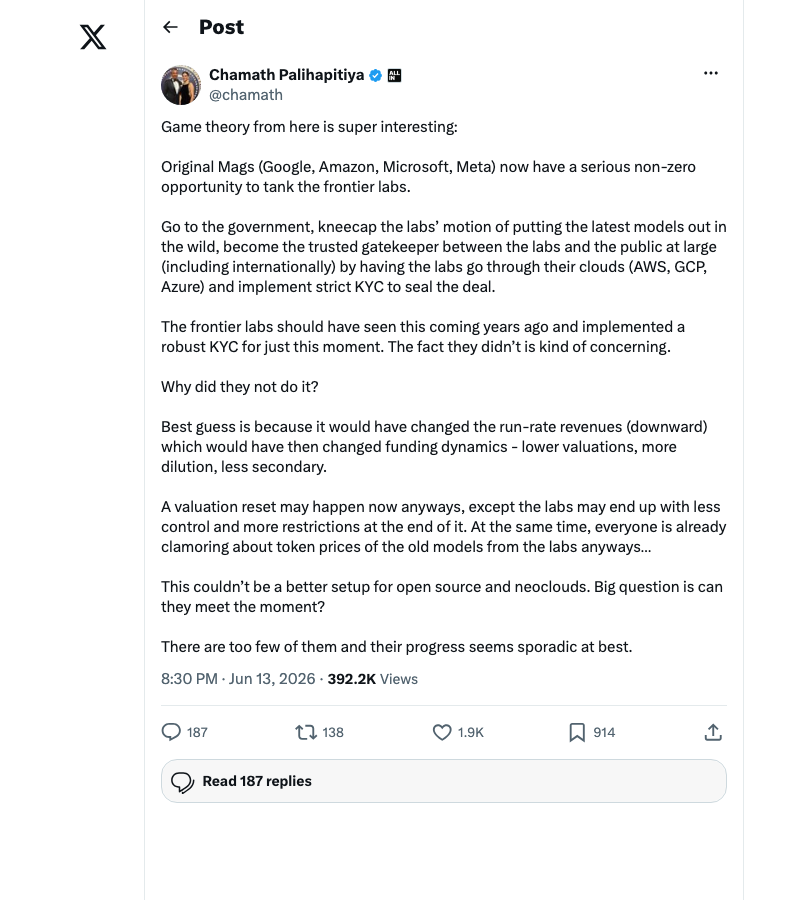
Chamath Palihapitiya laid out the game theory explicitly: incumbents can use government regulation to kneecap frontier labs. If that’s the new normal — and the Fable 5 ban suggests it might be — then the rational response is to build infrastructure that’s model-agnostic by design.
The Security Countercurrent
NVIDIA’s SkillSpector deserves its own section because it represents a maturity inflection point. The scanner identifies 64 vulnerability patterns across 16 categories in agent skill definitions. Their research found that 26.1% of skills contain at least one vulnerability.
That number is both alarming and encouraging. Alarming because a quarter of the skills ecosystem has security holes. Encouraging because it means the ecosystem is large enough and important enough for NVIDIA to build dedicated security tooling for it.
As Silenceper’s trend analysis noted: “Competition is moving from model answers to installable, reusable, verifiable work methods.” The key word is verifiable. SkillSpector exists because skills are becoming engineering assets that need the same governance as any other code artifact — dependency scanning, vulnerability disclosure, version pinning.
This is the lifecycle of every infrastructure layer: first adoption, then standardization, then security tooling, then compliance frameworks. Agent harnesses are somewhere between standardization and security tooling. The model layer is still in the “which one is best” phase — a commodity race.
The Orchestration Tools That Survived the Ban
We covered the best agent orchestration tools in 2026 back in March. The Fable 5 ban stress-tested every one of them. Here’s what the ban revealed about architectural resilience:
Multi-model routing survived. Teams using harnesses with provider abstraction — where the model is a config parameter, not a hardcoded dependency — swapped to Opus 4.6 or GPT-5.5 within hours. The orchestration logic, skill definitions, and quality gates didn’t change.
Single-model pipelines broke. Teams that had fine-tuned their prompts specifically for Fable 5’s capabilities, or that relied on Fable 5’s unique strengths in specific domains, faced a harder migration. The model-specific optimizations that gave them an edge became liabilities overnight.
Skills-based architectures were the most resilient. Frameworks like Superpowers that define capabilities as discrete, testable skill units made the model swap nearly invisible. Each skill has its own test suite. If the tests pass with the new model, the skill works. If they don’t, you know exactly which capability degraded and can write a targeted fix.
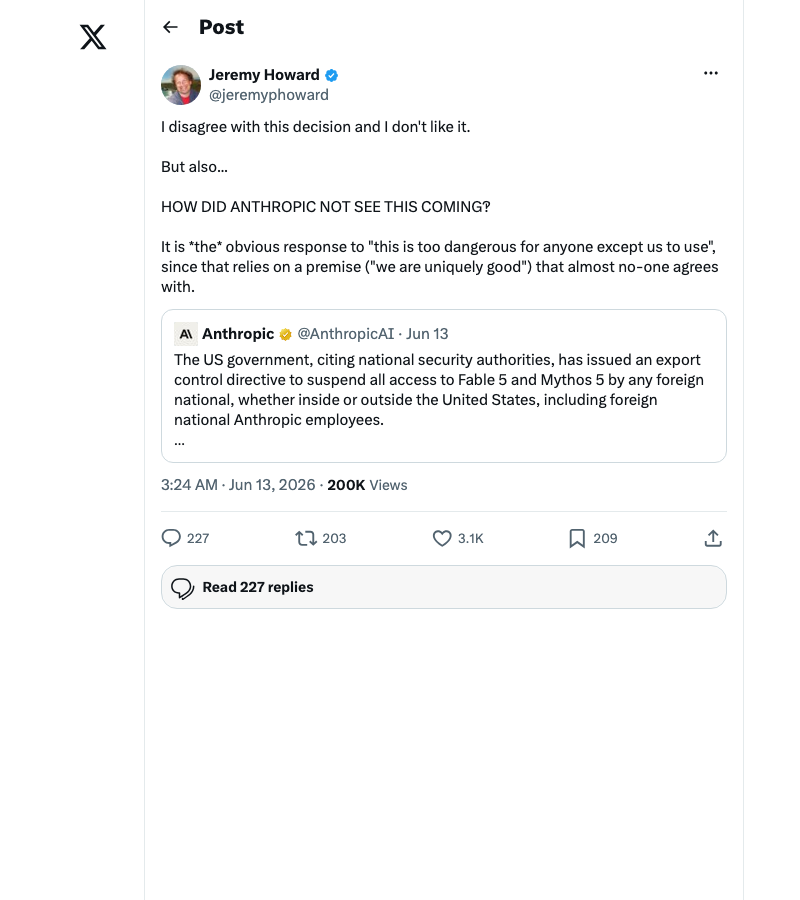
Jeremy Howard’s critique — “How did Anthropic not see this coming?” — applies equally to any team that built a single-model dependency into their agent infrastructure. The writing was on the wall: export controls, safety recalls, and competitive regulatory capture are now tools in the AI industry’s playbook.
What This Means for Your Architecture
If you’re building agent systems today, the Fable 5 ban offers five concrete architectural lessons:
1. Abstract the model layer. Your harness should treat the model as a pluggable component. Provider, model name, and API format should be configuration, not code. When the next ban hits — and the prediction markets give it a 38% chance of becoming systematic policy — you want a config change, not a sprint.
2. Invest in skill definitions, not prompt engineering. Prompts are model-specific. Skills are model-agnostic. A well-defined skill specifies inputs, outputs, validation criteria, and fallback behavior. It works with any model that meets the capability threshold.
3. Build multi-provider fallback chains. Your orchestration layer should maintain ranked fallback lists: primary model, secondary model, degraded-mode model. The Fable 5 ban happened on a Thursday evening. Teams with fallback chains were back online before Friday morning. Teams without them spent the weekend rewriting prompts.
4. Run SkillSpector (or equivalent) on your skills. If 26.1% of skills in the wild have vulnerabilities, assume yours do too. Security scanning isn’t optional for production agent infrastructure — it’s the same hygiene as running npm audit on your dependencies.
5. Test with multiple models continuously. Don’t wait for a ban to discover which of your skills degrade on a different model. Run your skill test suite against at least two providers in CI. The delta between providers is your model-dependency risk score.
The Bigger Picture
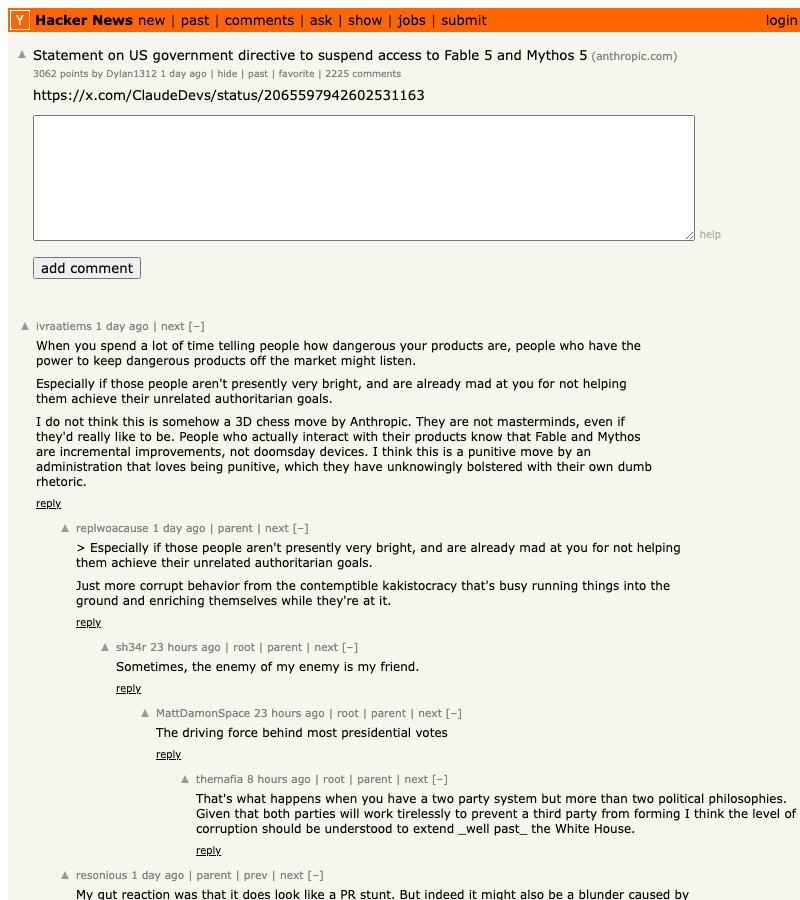
The top comment on the Hacker News thread captured the mood: “We have reached the max of model capabilities the US allows to be made public.” Whether that’s literally true matters less than the perception. The chilling effect is real, and it changes the calculus for every team building on frontier models.
But here’s the contrarian read: the ban is actually good for the orchestration ecosystem. Every model-policy shock pushes more investment toward model-agnostic infrastructure. Every export-control action makes the case for harness engineering stronger. The more volatile the model layer becomes — through bans, safety recalls, pricing changes, or capability regressions — the more valuable the stable orchestration layer above it.
The harness-moat thesis isn’t about predicting which models will be banned next. It’s about building architecture that doesn’t care. The teams that invested in orchestration infrastructure before June 12 didn’t need to predict the ban. They just needed to build systems where the model is a parameter, not a foundation.
That’s the moat. Not the model you run. The harness you built around it.
The Fable 5 ban dropped three days after launch. Read our coverage of the best agent orchestration tools that survived it, or explore agent frameworks on AgentConn.